

January 2024
In the last month, we added the ability to batch upload and extract from documents in the Sensible app. We also improved the user experience by adding a new Integrations tab for developers, and by auto-extracting data from new user's first documents. We improved LLM-based methods, and added advanced options for layout-based extractions, including the ability to transform extracted fields with your own custom logic.
New feature: Batch extract up to 5,000 documents in the Sensible app
You can now extract high volumes of documents through the Sensible app, in addition to extracting in volume through the Sensible API or SDK. Upload a batch of up to 5,000 documents at a time directly to the Extract tab in the Sensible app. You can download the data in Excel format to feed into your extraction workflow, or you can consume the JSON data through Zapier or fetch the completed extractions using the Sensible API or SDK. For more information, see Extract up to 5,000 documents concurrently with batch extract.

Improvement: Query method and Summarizer method updated from GPT-3 to GPT-3.5 Turbo
We've updated the large language model (LLM) that powers the Query and Summarizer methods from GPT-3 to GPT-3.5 Turbo. For more information, see Migrating off deprecated OpenAI models in a production system.
Improvement: Qualify LLM accuracy with "second opinion" confidence signals
Sensible has improved confidence signals for qualifying LLM accuracy. Sensible now prompts for confidence signals in a separate call to a second LLM model. This new approach offers several improvements:
- We've reduced model bias in the confidence signal by using two different LLM models.
- We've added a new confidence signal,
incorrect_answer. Previously, we prompted a single LLM to provide the answer and assess its confidence in the answer. Now the LLM providing the confidence signal can assess correctness by comparing the answer from the first LLM with the source document excerpt, or "context." - Sensible no longer prompts the LLM to return its answer in JSON. This eliminates a bug where asking the LLM to return a Boolean or other typed answer sometimes resulted in the LLM returning invalid JSON. Now you can prompt the LLM to return the answer as any type, and then you can optionally use Sensible types to validate that the returned value is of the type you want.
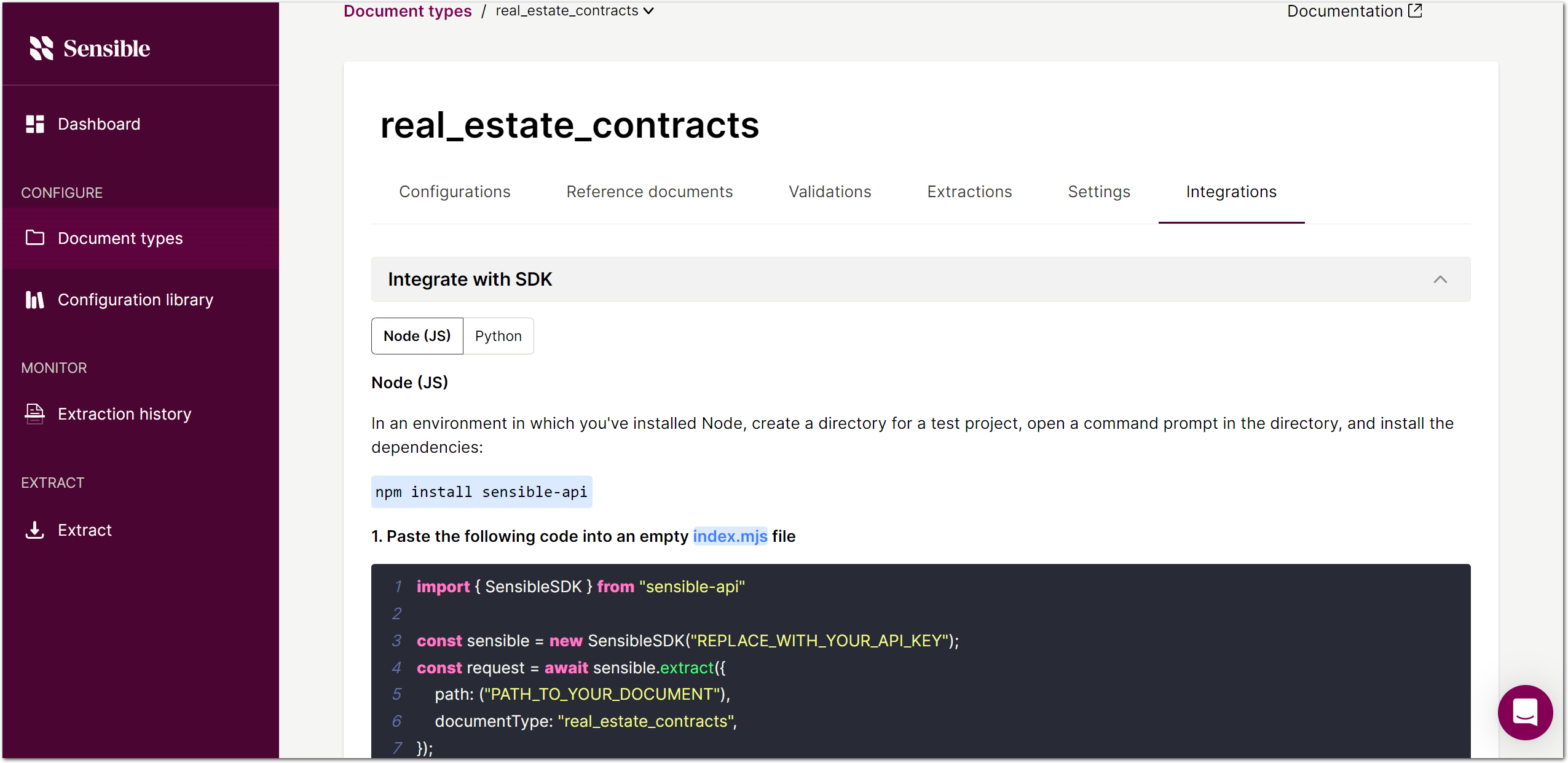
UX improvement: Integrations tab for developers in the Sensible app
Developers can now copy code snippets specific to a document type from the new Integrations tab. Click on a document type, then click Integrations.
Expand the Integrate with SDK section to copy a code example for that document type in Python or Node. Don't forget to paste your API key and the path to your document into the example.
Expand the Integrate with API section to copy the API endpoint for this document type.
UX improvement: Auto-extract when you upload your first document
We've made onboarding for new users easier than ever. In addition to providing a new user with guided onboarding steps when they upload their first document, Sensible now automatically creates extracted fields:
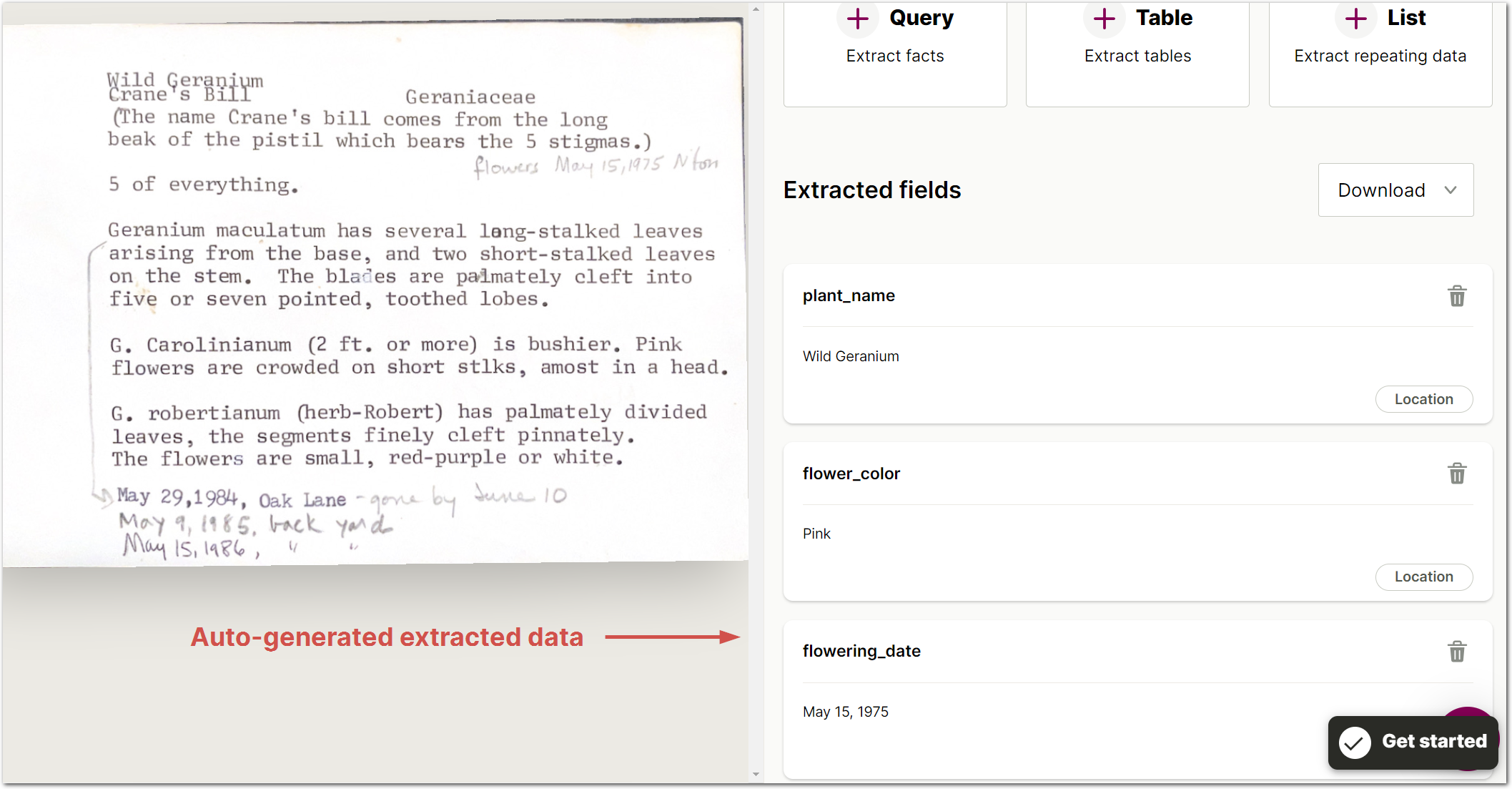
Sensible uses LLMs to create the fields with the Query method and extract relevant data from the document. You can then publish this configuration as-is, modify the auto-generated fields, or extract your own tables or lists. For example, in the preceding screenshot, you can author a field using the List method to capture all flowering dates, not just the first-mentioned flowering date.
Improvement: Filter pages for LLM-based methods with the new Page Range parameter
With the new Page Range parameter for LLM-based methods, you can narrow down the document pages in which Sensible searches for the answer to your LLM prompt. Sensible ignores other pages. For example, use this parameter to improve performance, or to avoid extracting unwanted data if your prompt has multiple candidate answers. For more information, see the Page Range parameter documentation in the Advanced prompt configuration topic.
Improvement: Extract checkboxes inside tables
For a subset of Table methods, Sensible now supports returning true or false for selected or unselected checkboxes in table cells. For example, for a table cell containing the text "✅ *Check pricing plan for details" , Sensible returns "[true] *Check pricing plan for details". For information about which Table methods support checkboxes in cells, see Choosing a Table method.
New feature: Transform fields using your own logic with the new Custom Computation method
You can now create custom Computed Field methods to transform extracted data with your own logic. For example, get the sum of two fields, or return a Boolean indicating if a field's output is non-null. For more information, see the Custom computation topic.
New feature: Transform tables using the new Add Computed Fields method
You can now transform tables using the new Add Computed Fields method, for example, to ensure consistent output across different document formats.
In the following example, Insurer A excludes the vehicle VIN and model from their policy limits table. In contrast, Insurer B includes the vehicle VIN, model, and make in their limits table:
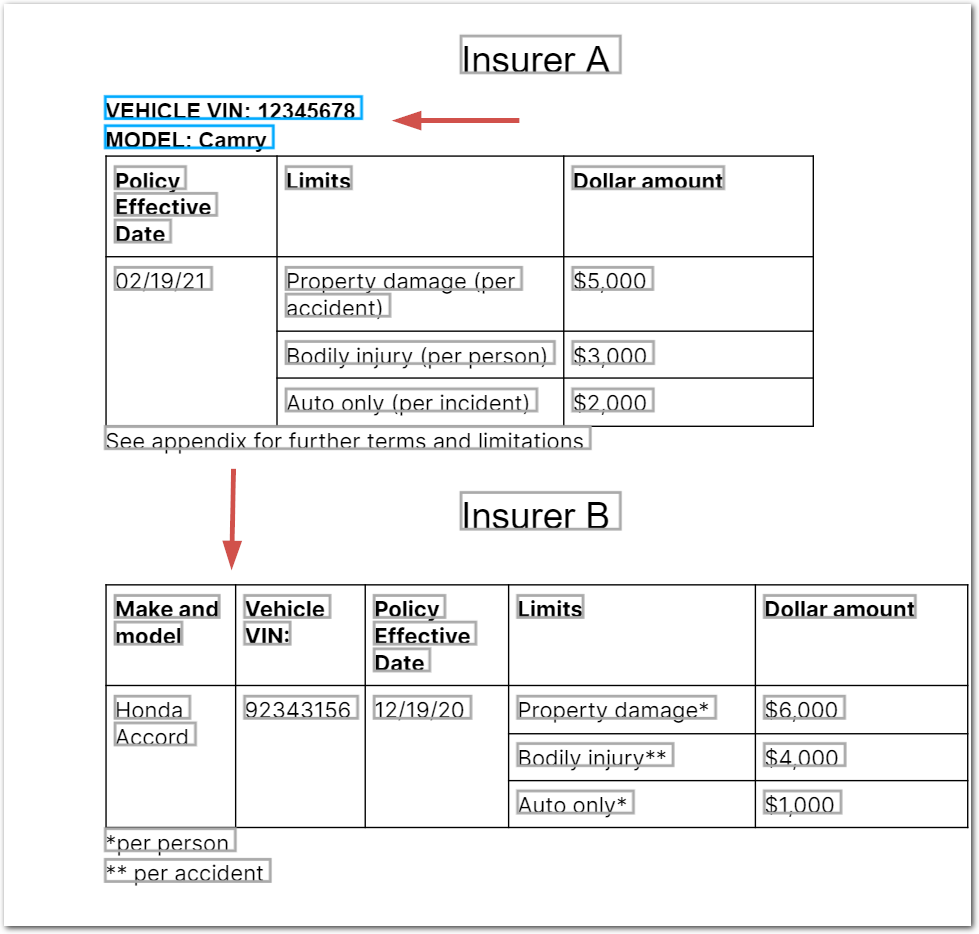
You can use the Add Computed Fields method to ensure that each table contains the same field IDs (vin, policy_start, limits, amount, and model):
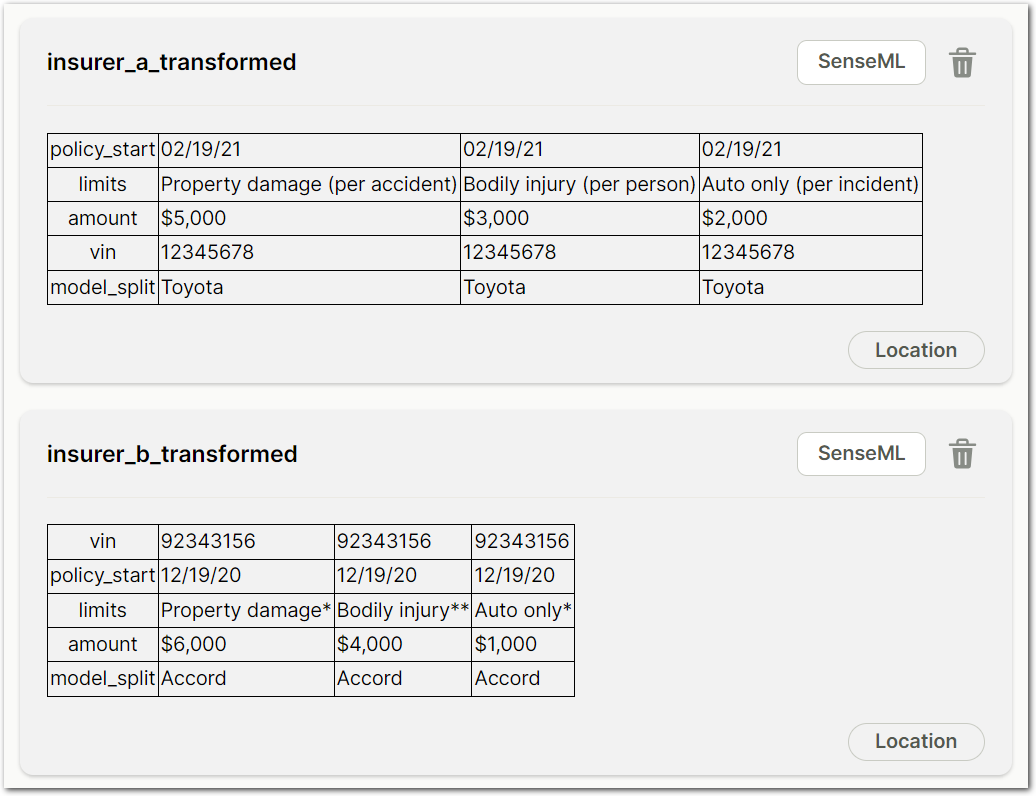
For more information about this example, see the Add computed fields topic.