

Summarizer
Deprecated
This method is deprecated. Configure the Source ID parameters on the Query Group and List methods to replace this method.
Description
Transforms short snippets of free text using an LLM. The Summarizer computed field method takes as input another extracted field's output, and transforms the text based on prompts or short samples of extracted values you provide. Use this method to transform another method's output when you can't use types or other computed field methods. For example, if you use the Row method to return an inconsistently formatted ranking (first, 1st, 1), then you can use this method to consistently format the ranking. You can reformat with instructions like reformat each inconsistently formatted instance of rank as a word (i.e. \"first\" not \"1st\" or \"1\") .
Parameters
The following parameters are in the computed field's Method parameter:
| key | value | description |
|---|---|---|
| id (required) | summarizer | The Anchor parameter is optional for fields that use this method. If you omit an anchor, Sensible searches the entire document for the data you want to extract. |
| source_id (required) | field ID | Specifies a field whose output is a snippet of text with the information you want to transform. |
| fields (required) | string array | IDs of the fields you want to extract. These IDs have an impact on the free-text extraction, so choose names that have a meaningful relationship to the target data to extract. For example, for a dollar amount of rent to extract, rent, rents, and rent_in_dollars are good naming choices. |
| instructions | string | Prompt for the LLM, describing how to transform information from the text in the Source ID parameter. For more information about how to write prompts, see Query Group tips. For an example of using this parameter, see the Examples section. |
| samples | object array | Short snippets of text similar to the text in the Source ID parameter, with examples of the information to extract. Use in addition to the Instructions parameter to increase the LLM's accuracy. Contains these parameters: prompt (string): An example of the sort of free text that you want to transformvalues (string array): The target information to transform from this prompt. This array is a parallel array to the Fields parameter's array. Parallel arrays are the same length and same sequence. If the LLM can't find the target information in the Source ID parameter, it can generate an arbitrary value. To override this behavior, specify a Sample parameter whose Prompt parameter has a text snippet that's missing the target data, and whose Values array indicates the data is missing (for example, "N/A" or "not found").For an example of using this parameter, see the Examples section. |
Examples
The following example shows using the Summarizer method to:
- Enforce consistent formatting for extracted class rankings.
- Parse an extracted address into its constituent parts.
Config
{
"fields": [
{
/* get historical data on class ranks
for student Sanchez */
"anchor": "sanchez",
"id": "sanchez_ranks",
"method": {
"id": "row",
"position": "right"
}
},
{
/* enforce consistent formatting for the extracted ranks */
"id": "ranks_reformatted",
"method": {
"id": "summarizer",
"source_id": "sanchez_ranks",
"instructions": "reformat each inconsistently formatted instance of rank as a word (i.e. \"first\" not \"1st\" or \"1\") then return the ranks",
"fields": [
"rank"
],
"samples": []
}
},
{
"method": {
/* get the high school's info */
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
{
"id": "high_school_name",
"description": "high school's name ",
"type": "string"
},
{
"id": "high_school_addr",
"description": "high school's address",
"type": "string"
}
]
}
},
{
"id": "address_reformatted",
"method": {
"id": "summarizer",
"source_id": "high_school_addr",
/* break the address into its separate parts */
"instructions": "Parse the provided address into its constituent parts: street, city, state, postal code, and country. Convert state abbreviations to full state names, and infer the country if not explicitly provided.",
"fields": [
"street",
"city",
"state",
"postalCode",
"country"
],
"samples": [
{
/* provide an example of how to handle missing address components */
"prompt": "145 Park Lane, apt B Florida 33101",
"values": [
[
"145 Park Lane, apt B",
"No City",
"Florida",
"33101",
"United States"
]
]
},
]
}
},
]
}Example document
The following image shows the example document used with this example config:
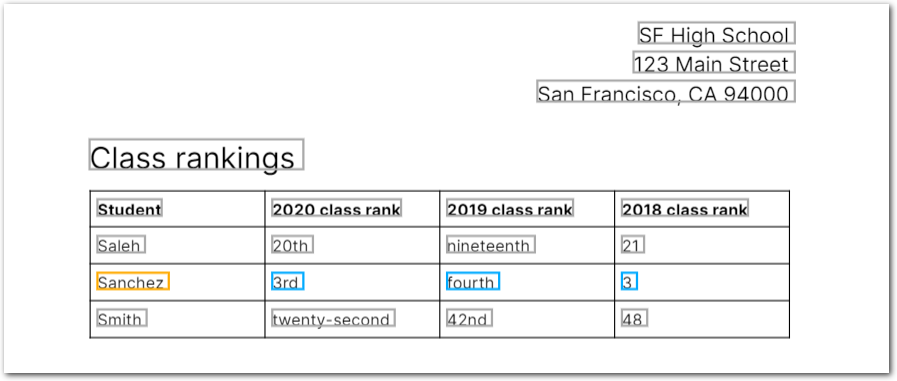
| Example document | Download link |
|---|
Output
{
"sanchez_ranks": {
"type": "string",
"value": "3rd fourth 3"
},
"ranks_reformatted": [
{
"rank": "third fourth third"
}
],
"high_school_name": {
"value": "SF High School",
"type": "string",
"confidenceSignal": "confident_answer"
},
"high_school_addr": {
"value": "123 Main Street, San Francisco, CA 94000",
"type": "string",
"confidenceSignal": "confident_answer"
},
"address_reformatted": [
{
"street": "123 Main Street",
"city": "San Francisco",
"state": "California",
"postalCode": "94000",
"country": "United States"
}
]
}Updated 7 months ago