

Types
Filter and format extracted data using the Type parameter in a Field object.
For example, the following field returns null unless it finds data that Sensible recognizes as a number:
{
"fields": [
{
"id": "typed_field",
"type": "number",
"anchor": "duration in years:",
"method": {
"id": "label",
"position": "right"
}
},
]
}As an alternative to types, you can use LLM-based fields to format and filter data. For example, instead of using the Compose type, you can use the Source IDs parameter on the Query Group method.
The following types are available:
TYPES
Address
Boolean
Currency
Date
Distance
Images
Name
Number
Paragraph
Percentage
Phone Number
String
Table
Weight
ADVANCED TYPES
DEPRECATED TYPES
Address
Returns USA-based addresses. By default, Sensible recognizes single- or multi-line addresses isolated from other lines in "block" format. For example, "type":"address" recognizes address such as:
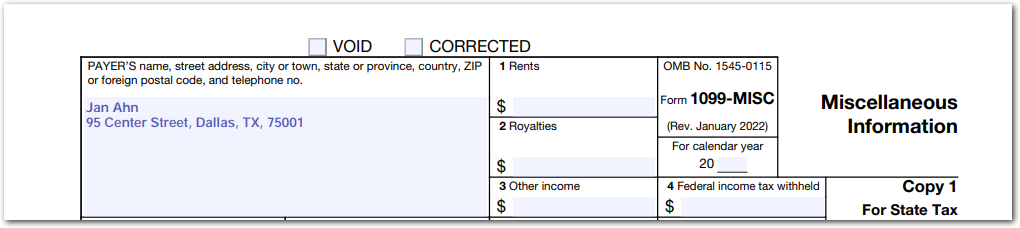
Use the Block Format parameter to recognize addresses embedded in non-address lines, for example, use:
"type": {
"id": "address",
"block_format": false
} to find addresses in paragraphs:

Example output
{
"value": "11 Center Street\nAmherst, MA 01002",
"type": "address"
}Formats recognized
With either block or in-line address, Sensible recognizes these formats:
- City, State, Zip, and variant representations of these elements such as abbreviations
- Digits, Street, City, State, Zip, and variant representations of these elements such as abbreviations
- PO boxes with a number represented in digits
- Lists of addresses in the preceding formats
- Addresses that span multiple lines. To enable this behavior, Sensible joins the lines returned by the method using whitespaces as the separators, and finds the type in the joined text.
Sensible is less sensitive to non-address text if you configure "block_format": false:
| Block | In-line | |
|---|---|---|
| Newlines optional | yes | yes |
| Trailing or leading non-address text allowed in starting or ending address lines | no | yes |
| Non-address text allowed between address elements | no | no |
For example:
# block formats
123 Waverly Pl
San Francisco, CA
941104123
San Francisco, CA 94110
123 Waverly Pl San Francisco, CA 941104123
PO BOX 1058 San Francisco, CA 94110
# inline format
the shipping address is 123 Waverly Pl
San Francisco, CA, 94110. The billing address is the same.
This type doesn't match text that lacks a zip code, such as 11 Center Street, Amherst, MA.
Boolean
Returns true for the following case-insensitive strings:
true
yes
yReturns false for the following case-insensitive strings:
false
no
nExample output:
{
"source": "YES",
"type": "boolean",
"value": true,
}Currency
You can define this type using concise syntax, or you can configure options with expanded syntax.
Simple syntax
Syntax example
"type": "currency"
Output example
Returns USA dollars as absolute value. For example,
{
"source": "3 bil",
"value": 3000000000,
"unit": "$",
"type": "currency"
}Formats recognized
Sensible by default recognizes USA decimal notation (for example, 1,500.06). Recognizes abbreviated quantities, such as k for thousand.
To recognize European decimal notation (for example, 1.500,06), see the following configurable syntax section.
Recognizes digits with the following formatting:
-
dollar sign, optional commas every three digits, optional cents after period
-
commas every three digits, optional cents after period
-
no dollar sign, up to six digits without commas as sole line contents. Allow up to nine digits if cents are present.
Recognizes abbreviated and written-out quantities as follows:
- thousand, k
- million, mil, mm, m
- billion, bil, b
- trillion, t
For example:
$1k
5k
1,000,000.056
$5.33
1 mm
3 bil
2 thousandThis type doesn't match text such as one million or 123456789.
Configurable syntax
Use configurable syntax to change the default recognized formats.
Example syntax
"type":
{
"id": "currency",
"currencySymbol": "€",
"requireCurrencySymbol": true,
"thousandsSeparator": ".",
"decimalSeparator": ",",
"maxValue": 10000,
"roundTo": 2
}Example output
{
"source": "€3.567,01",
"value": 3567.01,
"unit": "€",
"type": "currency"
}Parameters
| key | value | description |
|---|---|---|
| id (required) | currency | |
| requireCurrencySymbol | boolean. Default: false | Requires a currency symbol preceding the amount. |
| currencySymbol | string or object. Default: $ | The text to recognize as a currency symbol, for example "€" or "EURO". The text must precede the amount. This parameter sets the Unit parameter in the output. To specify multiple currencies to recognize, use this parameter to specify a lookup table. The table maps source text to the Unit parameter. For example, the following lookup table recognizes currency codes and symbols for dollars and euros, and outputs symbols to the Unit parameter: "currencySymbol": { "$": "$", "€": "€", "USD": "$", "EUR": "€", "default": "€" }If the source text doesn't include a currency symbol, Sensible uses the default specified in the lookup table. If the lookup table doesn't include a default, Sensible falls back to the $ symbol. |
| requireThousandsSeparator | boolean. Default: false | Requires a thousands separator in numbers with a thousands place. |
| thousandsSeparator | string. Default: , | The separator to require, for example . |
| decimalSeparator | string. Default: . | For numbers with a decimal place, specify the separator, for example ,. |
| maxDecimalDigits | number. Default: 4 | The maximum number of decimal digits to recognize. |
| maxValue | number. Default: infinity | The maximum currency amount to recognize. Use this to extract an amount with a known range. For example, use it as an alternative to the Tiebreaker parameter, or to extract one currency amount among several returned by a method like the Document Range or Box method. |
| minValue | number. Default: infinity | The minimum currency amount to recognize. Use this to extract an amount with a known range. |
| relaxedWithCents | Boolean. default: false | Use this parameter when poor-quality scans or photographed documents result in erroneous OCR output for the decimal separator or thousands separator. If true, Sensible overrides all other Currency type parameters, outputs USD currency, and recognizes the following number format as a currency: - any number of digits mixed with <fuzzySeparator> characters, followed by- one <fuzzySeparator> character, followed by- two digits (for the cents) where a <fuzzySeparator> character is any of the following common erroneous OCR outputs for a period or comma: .,;: _ (period, comma, semicolon, colon, space, underscore)For example, if you set this parameter to true, then for the erroneous OCR output "7.859:36", Sensible returns: {"source": "7.859:36", "type": "currency", "unit": "$", "value": 7859.36} |
| accountingNegative | default, anyParentheses, bothParentheses, suffixNegativeSign Default: null | Replaces the deprecated Accounting Currency type. Specifies to recognize accounting sign conventions for negative numbers.null Sensible recognizes negative numbers as described in the preceding formats recognized section.bothParentheses - Sensible assigns a negative value to a number prefixed and suffixed by parentheses.anyParentheses - Sensible assigns a negative value to a number that includes any parentheses as a suffix or prefix. Use this option to handle OCR errors, where an opening or closing parenthesis can be incorrectly recognized as other characters.suffixNegativeSign - Sensible assigns a negative value to number suffixed by a negative sign.default Replaces the behavior of the Accounting Currency type for backward compatibility. The equivalent of bothParentheses and suffixNegativeSign. |
| alwaysNegative | boolean | If true, Sensible assigns a negative value to a number and ignores sign symbols in the document. For example, use this to capture values in the debit column of an accounting document, where negative signs are omitted. |
| removeSpaces | boolean | Removes whitespace in a line for better currency recognition. For example, changes the line $ 12.45 to $12.45. |
| roundTo | number of decimal places to round up to. | Rounds up to the specified decimal place. For example if you specify "roundTo": 3 then Sensible rounds 0.1234 to 0.123. If you specify "roundTo": 2 and "decimalSeparator": "," then Sensible rounds 5,249 to 5,25. |
Date
You can define this type using concise syntax, or you can configure options with expanded syntax.
Sensible matches dates that span multiple lines. To enable this behavior, Sensible joins the lines returned by the method using whitespaces as the separators, and finds the type in the joined text.
Simple syntax
Syntax example
"type":"date"
Output example
Returns an ISO 8601-formatted date-time. For example:
{
"source": "Feb 1, 21",
"value": "2021-02-01T00:00:00.000Z",
"type": "date"
}Formats recognized
Sensible recognizes the following date formats by default:
"%m/%d/%Y",
"%m/%d/%y",
"%m/%Y",
"%b %d,? %Y",
"%b %d,? %y",
"%b %dst,? %Y",
"%b %dst,? %y",
"%b %dnd,? %Y",
"%b %dnd,? %y",
"%b %dth,? %Y",
"%b %dth,? %y",
"%b %drd,? %Y",
"%b %drd,? %y",
"%m-%d-%Y",
"%m-%d-%y",
"%Y-%m-%d",
"%Y%M%D"See the following configurable syntax section for definitions of the field descriptors in the preceding list.
The following are examples of date formats that Sensible recognizes:
# English (default)
5/17/2018
november 30, 1955
Feb 1, 21
June 7th, 2021
Jan. 9th, 09
# Spanish
7 de enero de 2018
30 de septiembre de 2027
15 de setiembre de 2026
# Italian
21 marzo 2021
30 settembre 2027Configurable syntax
Syntax example
The following example:
"type":
{
"id": "date",
# recognizes 4 custom formats, e.g., JAN-31st-22, 800325, JAN\31\2022, or jan 2022
"format": ["%b-%d[a-z]{2}-%y$", "%y%M%D", "%b\\\\%d\\\\%Y", "%b\\s*?%Y"]
}Recognizes the following date formats and ignores all default formats:
| format | example | example output |
|---|---|---|
"%b-%d[a-z]{2}-%y$" | JAN-31st-22, February-3rd-21 | "value": "2022-01-31T00:00:00.000Z" |
"%y%M%D" | 800325 | "value": "1980-03-25T00:00:00.000Z", |
"%b\\\\%d\\\\%Y" | JAN\31\2022 | "value": "2022-01-31T00:00:00.000Z" |
"%b\\s*?%Y" | jan 2022 | "value": "2022-01-01T00:00:00.000Z" |
Parameters
| key | value | description |
|---|---|---|
| id (required) | date | Returns datetime. Sensible outputs the time as midnight UTC. |
| format | JS regex or array of JS regexes | Custom date formats override the defaults listed in the simple syntax section. See the following table for a list of the field descriptors. The field descriptors are concise syntax for regular expressions. You can use JavaScript-flavored regular expressions ("regex") with these field descriptors to define custom date formats. Double escape special characters since the regex is in a JSON object (for example, \\s, not \s , to represent a whitespace character). |
| language | en (default), es,it | Recognizes month and month abbreviations in the specified language:en - Englishes - Spanishit - Italian |
The following table lists the field descriptors you can use to define a custom format other than the default formats listed in the simple syntax section.
| field descriptor | regex | notes | example |
|---|---|---|---|
%b | for each month, case-insensitive pattern like january OR jan\.? | Abbreviated month name, with or without periods, or full month name. | Jan, Feb, ..., Dec. January, February, ..., December |
%y | [0-9]{2} | Two-digit year. Values in the range 69–99 refer to years in the twentieth century (1969–1999); values in the range 00–68 refer to years in the twenty-first century (2000–2068). Tips: If you want to recognize two-digit years and exclude four-digit years, add an end-of-line regex special character $ in formats like "%m/%d/%y$" so that you don't incorrectly match dates like 02/03/1998 as 2019-02-03T00:00:00.000Z. If you want to match both two- and four-digit years, you don't need the $ character. Instead you need to specify the four-digit format first, for example, ["%b-%d-%Y","%b-%d-%y"]. | 00, 01, ..., 99 |
%Y | [0-9]{4} | Four-digit year (year with century as a decimal number). | 2013, 2019 etc. |
%m | [0-9]{1,2} | The month number, unpadded or zero-padded. | 1,...,12 01,...,12 |
%M | [0-9]{2} | Two-digit ("zero-padded") month number (01-12). | 01,...,12 |
%d | [0-9]{1,2} | The day number, unpadded or zero-padded | 1,...,31 01,...,31 |
%D | [0-9]{2} | Two-digit ("zero-padded") day number (01-31). | 01,...,31 |
Distance
Returns miles and kilometers. Recognizes digits followed optionally by kilometers, miles, or their abbreviations. For example:
3,001.5 kilometers
2 km
1.5 kms
1 mile
4 mi
45Example output:
{
"source": "3,001.5 kilometers",
"value": 3001.5,
"unit": "kilometers",
"type": "distance"
}Images
Use this solely with the Document Range method to return image metadata.
Name
Simple syntax
Syntax example
"type": "name"
Output example
Returns one or more names. For example:
{
"source": "Richard & Ann Spangenberg",
"type": "name",
"value": [
"Richard Spangenberg",
"Ann Spangenberg"
}Formats recognized
Doesn't recognize a list of names more than 6 words long. Doesn't recognize lists of three or more names such as last1, last2, & last3
Recognizes names of the formats below, and variant representations of these elements such as abbreviations.
- first last
- first1 last1 and first2 last2
- last, first1 and first2
- first1 and first2 last
- first1 last1, first2 last2,... firstN, lastN
For example:
John R. Smith Sr
Richard & Ann Spangenberg
DuBois, Renee and Lois
Argos Fullington, Jax Odenson, Ollie LongstreetConfigurable syntax
Example syntax
"type":
{
"id": "name",
"capitalization": "allCaps"
}Example output
{
"source": "Richard & Ann Spangenberg",
"type": "name",
"value": [
"RICHARD SPANGENBERG",
"ANN SPANGENBERG"
}Parameters
| key | value | description |
|---|---|---|
| id (required) | name | |
| capitalization | allCaps, firstLetter. Default: no change to source capitalization | Formats the output in all uppercase, or with the first letter of each word capitalized. |
Number
Simple syntax
Syntax example
"type": "number"
Output example
{
"source": "123456789",
"value": 123456789,
"type": "number"
}Formats recognized
By default, recognizes digits in USA decimal notation, where thousands are separated by commas and the decimal place is denoted by a period. In detail, recognizes one or more digits, optionally followed either by:
-
commas preceding every three digits, optional digits after period, or by
-
digits after period
For example:
-3.1
3,500,053.78
1234567890To recognize numbers formatted like 3.061.534,45, configure the Thousands Separator and Decimal Separator parameters.
Configurable syntax
Example syntax
"type":
{
/* source text is 1,234.56989 */
"id": "number",
"roundTo": "2"
}Example output
{
"source": "1,234.56989",
"value": 1234.57,
"type": "number"
}Parameters
| key | value | description |
|---|---|---|
| id (required) | number | |
| roundTo | number of decimal places to round up to. | Rounds up to the specified decimal place. For example if you specify "roundTo": 3 then Sensible rounds 0.1234 to 0.123. |
| thousandsSeparator | string. Default: , | The separator to require, for example . |
| decimalSeparator | string. Default: . | For numbers with a decimal place, specify the separator, for example ,. |
Paragraph
Use with methods that return paragraphs, for example Document Range or Paragraph, to format the extracted text. By default, returns paragraphs formatted with newline characters (\n), instead of formatted as a single string.
Simple syntax
Syntax example
"type": "paragraph"
Output example
For any move in date that is after the 15th of the month, Tenant must pay a full month of rent in order to gain possession of the home. The prorated rent amount will be due the second month of lease.\n Every month thereafter, Lessee must pay rent on or before the 1st day of each month with 5 days of grace period. Excludes utility costs.\nFormats recognized
Sensible recognizes paragraphs separated by configurable vertical gaps, or "paragraph breaks." Sensible doesn't use paragraph margins, for example indentations, to detect paragraphs.
Configurable syntax
Use configurable syntax to change the formatting of the extracted text.
Example syntax
"type":
{
"id": "paragraph",
/* if you set this to true, also set `"prevent_default_merge_lines": true` for the document type using the Sensible API's Document Type endpoints */
"annotateSuperscriptAndSubscript": true
}Example output
For the following document:

When you set "annotateSuperscriptAndSubscript": true , Sensible formats the footnote symbols to indicate they're superscripted, for example, [^1]:
{
"lease_duration": {
"type": "string",
"value": "12/31/2023 [^1] . Thereafter, it shall be month-to-month on the same terms and conditions as stated herein plus $80.00 month to month charge, save any changes made pursuant to law, until terminated by notice of at least 30 days. [^2]\n[^1] Landlord shall send notice of new terms 30 days before current terms end. [^2] Proper 30 day notice (in writing or email) must be received by the Landlord."
}
}Parameters
| key | value | description |
|---|---|---|
| id (required) | paragraph | |
| annotateSuperscriptAndSubscript | Boolean. default: false | When true: - Sensible annotates subscript and superscript text with [^...] and [_...], respectively.- Sensible annotates end-of-page breaks with [EOP].- If you set this to true, also set "prevent_default_merge_lines": true for the document type using the Sensible API's Document Type endpoints. This ensures that Sensible interleaves the annotation symbols with the text instead of placing them at the end of the line. |
| allNewlines | Boolean. default: false | When true, Sensible inserts a newline (\n) in the output for every line break in the document text, and two newlines (\n\n), for every paragraph break.When false, Sensible inserts a newline for every paragraph break. |
| paragraphBreakThreshold | default: 0.4 | By default, Sensible detects paragraph breaks when the vertical gap between two lines is larger than 40% of the font height of the output line. Use this parameter to change the percentage. |
Percentage
Returns percent as an absolute value. Recognizes a percent formatted as digits in USA decimal notation (for example, 1,500.06), followed optionally by a whitespace, followed by a percent sign (%) .
For example:
20.1 %
20.1%
1,000.05%Example output
{
"source": "20.5%",
"value": 20.5,
"type": "percentage"
}Phone Number
Returns phone numbers:
-
Recognizes USA 10-digit phone numbers either with or without a country calling code. May be optionally formatted with parentheses, dashes, spaces, plus sign (+), or periods.
-
Recognizes international phone numbers if prefixed by a country calling code (for example, +91 for India).
Examples:
1-888-353-9578
+18883539578
888.353.9577
888 353 3264
888 353-3232
(207) 312-6767
+91 9999999999
+91 9999 999999
+91 9999-999999Example output
{
"type": "phoneNumber",
"source": "(855) 786-3246",
"value": "+18557863246"
}This type does not recognize country calling codes formatted with 00, for example, 0091 or 001.
String
Default type. Returns strings.
Example output
{
"type": "string",
"value": "3 bil"
}Table
Required when you define a table method.
Weight
Returns pounds and kilograms. Recognizes digits in USA decimal notation (for example, 1,500.06):
-
digits are in the format recognized by the Number type
-
"pounds", "kilograms", or their abbreviations follow the digits
For example:
1,000.4 kg
1 kilo
5.5 kilograms
6.00 lbs
1 pound
634.83Example output
{
"source": "6,000.01 lbs",
"value": 6000.01,
"unit": "pounds",
"type": "weight"
}ADVANCED TYPES
Compose
Returns a transformed type you define using an array of types. In the array, each successive type in the array takes the previous type's output as its input. For example, use this type:
- As a more syntactically concise alternative to the Regex method or to Computed Field methods. For example, you can write a field to capture a date-typed field, then transform the field's output with the Split method. Or, see the following example to transform dates using the Compose type.
- To transform table cell contents. As an alternative, see the NLP table method to transform table cell contents using large language models(LLMs).
- As an alternative to this type, see the Source ID parameters on the Query Group method. You can use this parameter to transform extracted data, for example,
format the extracted data in mm-dd-yyy format.
Parameters
| key | value | description |
|---|---|---|
| id (required) | compose | |
| types (required) | array of type objects | Each type in a compose array takes the output of the previous type as its input. If you specify a tiebreaker for a field using this type, the tiebreaker applies to the output of the last type in the array. |
Examples
Config
{
"fields": [
{
"id": "maintenance_records",
"anchor": "date",
"type": "table",
"method": {
"id": "fixedTable",
"columnCount": 2,
"columns": [
{
"id": "col1_date",
"type": {
"id": "compose",
"types": [
{
/* convert variable source date formats to standard format
YYYY-MM-DDT00:00:00.000Z */
"id": "date"
},
/* convert date type's output to YYYY-MM using a capturing group */
{
"id": "custom",
"pattern": "^([0-9]{4}-[0-9]{2})-[0-9]{2}",
/* optionally name a custom type */
"type": "date-YYYY-MM"
}
]
},
"index": 0
},
{
"id": "col2_description",
"index": 1
}
],
"stop": {
"type": "startsWith",
"text": "keep"
}
}
}
]
}Example document
The following image shows the example document used with this example config:
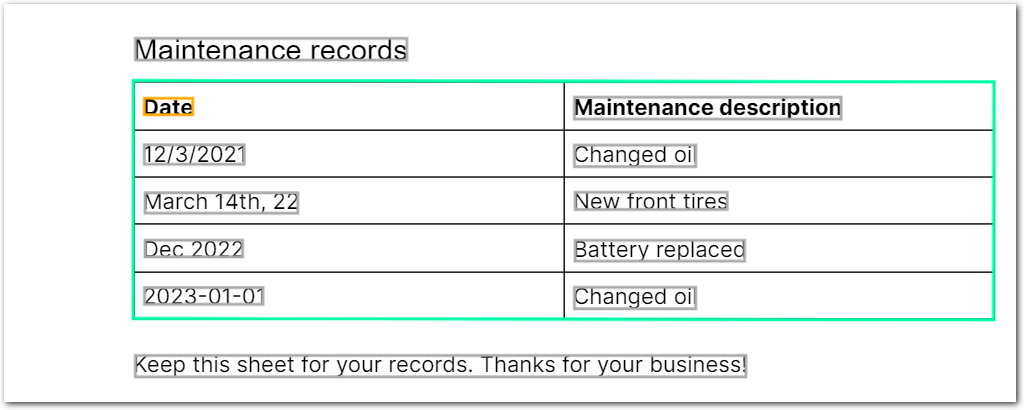
| Example document | Download link |
|---|
Output
{
"maintenance_records": {
"columns": [
{
"id": "col1_date",
"values": [
null,
{
"source": "2021-12-03",
"value": "2021-12",
"type": "date-YYYY-MM"
},
{
"source": "2022-03-14",
"value": "2022-03",
"type": "date-YYYY-MM"
},
null,
{
"source": "2023-01-01",
"value": "2023-01",
"type": "date-YYYY-MM"
}
]
},
{
"id": "col2_description",
"values": [
{
"value": "Maintenance description",
"type": "string"
},
{
"value": "Changed oil",
"type": "string"
},
{
"value": "New front tires",
"type": "string"
},
{
"value": "Battery replaced",
"type": "string"
},
{
"value": "Changed oil",
"type": "string"
}
]
}
]
}
}Custom
Use the Custom type to return all regular-expression pattern matches in source lines. For example, in the source text available appointment times include 12:45, 14:15, and 16:30 you can use the regular expression [0-9]{2}:[0-9]{2} to match 12:45, 14:15, and 16:30. By default, this type returns the first match (12:45). Take actions on your matches, for example:
- Configure which match to return using the Tiebreaker parameter or the first capturing group.
- Specify the match as a custom type, using this type's Type parameter. For example, create types for zip codes, time durations, customer IDs, and order numbers.
- Transform the match using the Compose type. For an example, see the Compose type.
Example syntax
"type":
{
"id": "custom",
"pattern": "Time\\:\\s*([0-9]{2}:[0-9]{2})",
"type": "time_24_hr"
}Example output
This type outputs strings. For example:
{
"source": "Time: 14:01",
"value": "14:01",
"type": "time_24"
}Parameters
| key | value | description |
|---|---|---|
| id (required) | custom | |
| pattern (required) | Valid JS regex | JavaScript-flavored regular expression. Returns the first match, or returns the first capturing group if specified. For full support for capturing groups, see the Replace type. As an alternative to capturing groups, use a tiebreaker, for example, "tiebreaker": "second". See the following section for an example.Double escape special characters since the regex is in a JSON object. For example, \\s, not \s , to represent a whitespace character.Sensible doesn't validate regular expressions for custom types. |
| flags | JS-flavored regex flags. | Flags to apply to the regex, for example: "i" for case-insensitive. The flag "g" is unsupported. As an alternative, use "tiebreaker": "join" to return all matches as one string. |
| matchMultipleLines | Boolean. default: false | If true, matches regular expressions that span multiple lines. To enable this behavior, Sensible joins each line returned by the method using a whitespace as the separator, and runs the regular expression on the joined text.^ matches the start of the first line returned by the method, and $ matches the end of the last line. For example, ^[0-9 ]+$ matches all the joined text returned by the method, if all the characters are digits or whitespaces. |
| type | String. default: string | Name for your custom type. For example, "time_24_hr" or YY-MM-date. |
Examples
The following example shows using a tiebreaker as an alternative to a capturing group to return one of several matches from the Custom type.
Config
{
"fields": [
{
"id": "last_appt",
"anchor": "available",
"method": {
"id": "box",
"includeAnchor": true,
/* return the last pattern match */
"tiebreaker": "last"
},
"type": {
"id": "custom",
/* match all 24-hr formatted times.
tiebreaker determines which of
3 matches to return */
"pattern": "[0-9]{2}:[0-9]{2}",
"type": "time_24_hr"
}
}
]
}Example document
The following image shows the example document used with this example config:
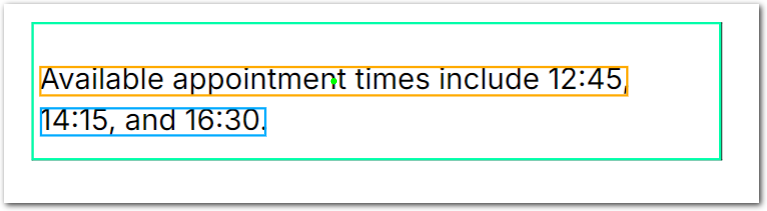
| Example document | Download link |
|---|
Output
{
"last_appt": {
"source": "16:30",
"value": "16:30",
"type": "time_24_hr"
}
}Replace
Use the Replace type to replace all instances of a regular-expression pattern match in source lines and return the transformed source lines as a string. For example, strip out whitespaces from the source text $ 5 00 0 and return $5000.
Parameters
| key | value | description |
|---|---|---|
| id (required) | replace | |
| pattern (required) | Valid JS regex | JavaScript-flavored regular expression. Replaces all matches. Supports capturing groups. See the following section for an example. By default, matches regular expressions that span multiple lines. To enable this behavior, Sensible joins each line returned by the method using a whitespace as the separator, and runs the regular expression on the joined text. Double escape special characters since the regex is in a JSON object. For example, \\s, not \s , to represent a whitespace character.Sensible doesn't validate regular expressions for custom types. |
| replaceWith (required) | string | Specifies the text with which to replace each match. For example, replace every digit in a string ("pattern:"[0-9]") with the character "x" ("replaceWith":"x"). For a matched string a12bc3 this returns axxbcx. Or, specifies to replace capturing groups. For example, "pattern": "(account)\\s(number)" and "replaceWith": "$2, $1" returns number, account. |
| flags | JS-flavored regex flags. Default: "g" | Flags to apply to the regex. for example: "i" for case-insensitive. Sensible always applies the flag "g" (global). |
Examples
The following example shows how to strip all whitespaces and unwanted characters from a number, and how to use capturing groups with the replace type.
Config
{
"fields": [
{
/* the source text contains unexpected whitespaces and capital letters due to line merging problems
use the Replace type to strip the whitespaces
and the Compose method to convert the stripped output
to a currency */
"id": "each_accident",
"anchor": {
"match": {
"text": "EMPLOYER'S LIABILITY",
"type": "includes"
}
},
"type": {
"id": "compose",
"types": [
{
"id": "replace",
/* find all capital letters and whitespaces */
"pattern": "[A-Z\\s+]",
/* strip them from the output */
"replaceWith": ""
},
/* convert the output of the Replace type to a currency */
"currency"
]
},
"method": {
"id": "region",
"start": "left",
"offsetX": 0,
"offsetY": 0.1,
"width": 3,
"height": 0.2,
"sortLines": "readingOrderLeftToRight",
}
},
{
/* this field shows the original string output,
which can't be converted to currency until the spaces and letters are removed */
"id": "_each_accident_raw",
"anchor": {
"match": {
"text": "EMPLOYER'S LIABILITY",
"type": "includes"
}
},
"method": {
"id": "region",
"start": "left",
"offsetX": 0,
"offsetY": 0.1,
"width": 3,
"height": 0.2,
"sortLines": "readingOrderLeftToRight",
}
},
{
"id": "proposed_exp_date",
"anchor": {
"match": {
"text": "proposed exp",
"type": "includes"
}
},
"type": {
"id": "replace",
/*regex pattern, using capturing groups */
"pattern": "([0-9]{2}).*?([0-9]{2}).*?([0-9]{4})",
/* outputs the capturing groups in a new order */
"replaceWith": "$3-$1-$2",
},
"method": {
"id": "region",
"start": "left",
"offsetX": 0,
"offsetY": 0.1,
"width": 3,
"height": 0.2,
"sortLines": "readingOrderLeftToRight",
}
},
]
}Example document
The following image shows the example document used with this example config:
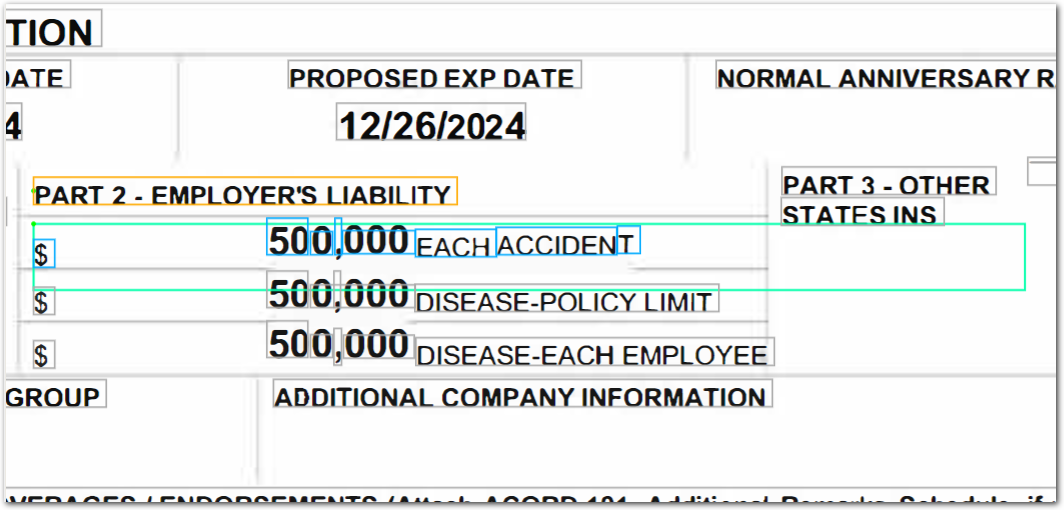
| Example document | Download link |
|---|
Output
{
"each_accident": {
"source": "$500,000",
"value": 500000,
"unit": "$",
"type": "currency"
},
"_each_accident_raw": {
"type": "string",
"value": "$ 50 0 , 000 ACCIDEN EACH T"
},
"proposed_exp_date": {
"source": "12/26/2024",
"value": "2024-12-26",
"type": "replaced_string"
}
}Any
Use the Any type to specify an array of possible types for a field. Sensible uses the first-matching type in the array. Use the Any type as a more concise syntactical alternative to defining an array of fallback fields of different types to capture variations in target data's formatting or type.
For example, to specify a field that Sensible might recognize as a currency, a number, or a string, depending on the document formatting, use the Any type:
{
"fields": [
{
"id": "total_charge",
"type": {
"id": "any",
"types": [
{
"id": "currency",
"requireCurrencySymbol": false,
"maxValue": 10000,
"roundTo": 2
},
"number",
"string"
]
}
}
"anchor": "total charge:",
"method": {
"id": "passthrough"
}
}
]
}If Sensible recognizes a currency, it can for example return:
{
"total_charge": {
"source": "$ 1,000",
"value": 1000,
"unit": "$",
"type": "currency",
}
} Or, if it fails to recognize the total charge as a currency but does recognize it as a number, it can fall back to returning:
{
"total_charge": {
"source": "1,000",
"value": 1000,
"type": "number",
}
}DEPRECATED TYPES
Accounting Currency
Deprecated. See Currency
Returns US dollar numbers. Supports negative numbers represented either with parentheses () or with the minus sign (-).
Recognizes digits in USA decimal notation (for example, 1,500.06):
- digits are in the format recognized by the Number type
- digits are optionally preceded or succeeded by a negative sign (-)
- digits are optionally preceded by a USA dollar sign ($)
Examples:
56,999
-$527.01
$527.01-
(1,000)
($400.567)Example output
{
"source": "($400.567)",
"value": -400.567,
"unit": "$",
"type": "accountingCurrency"
}Updated 3 months ago