

March 2022
In the last month, we released several new features, including support for extracting from image documents (PNG and JPEG), a powerful new column-recognition capacity in our Sections feature, the ability to add your own custom data types, and more.
New feature: Extract from PNG and JPEG documents
You can now use the Sensible API to extract data from PNG and JPEG images of documents, not just PDFs. Sensible OCRs photos of documents and then processes them exactly as it would other documents.
New feature: Recognize columns in sections
We added power and flexibility to sections with the ability to recognize columns in a section ("vertical sections"). This allows you to extract from a wide variety of complex table-like and column-like layouts, including tables nested in tables, table grids, and tables with both row labels and column labels.
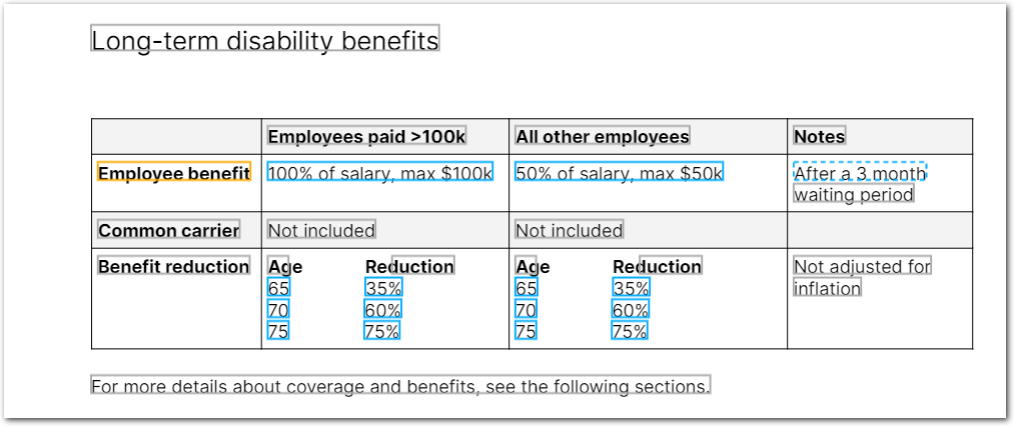
In order to extract repeated tables in vertical sections, we also added the ability to define relative coordinates in the Text Table method with the new Columns Relative To Anchor parameter.
New feature: Custom type
You're no longer limited by the types that Sensible defines; you can define your own custom type using regular expressions, for example for invoice numbers or time durations.
Improvement: Web app UX
You can now view each extraction in a portfolio separately in the extraction list in the Sensible app by clicking the extraction and navigating to each separate PDF in the portfolio.
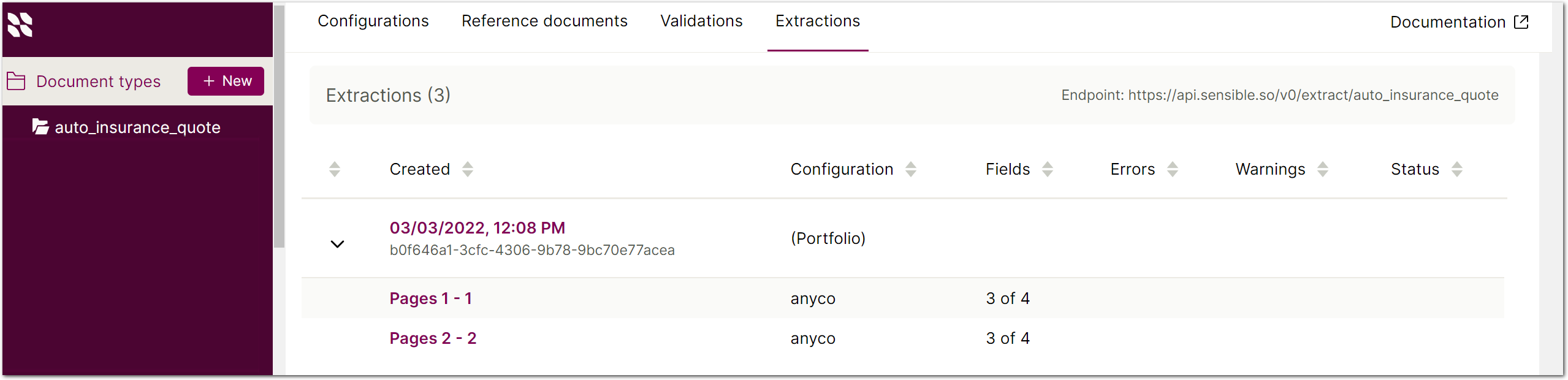
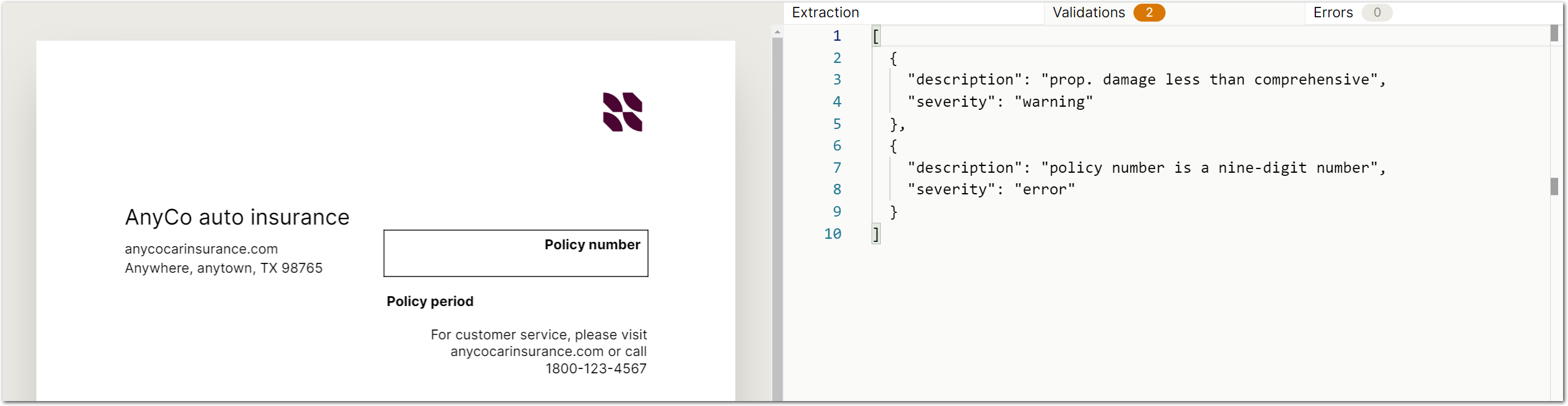
In the SenseML editor, the right pane now displays additional tabs so you can view not just the extraction, but also any validation messages or errors:
Improvement: Adaptive contrast for Box and Checkbox methods
Scanned documents can have off-white, mottled backgrounds. Sensible now automatically adjusts for such backgrounds when recognizing boxes and checkboxes.
New feature: Paragraph method
With the new Paragraph method, we added document layout recognition to enable you to extract paragraphs from column or multi-page layouts.
Improvement: Customizable Currency type
You can now customize recognizing the Currency type with options for delimiting characters, currency characters, and decimal place, for example to recognize non-USA currencies.
Improvement: Customizable Name type output
You can now standardize capitalization for the output of the Name type.
Improvement: Remove repeated headers with Fixed Table method
We improved handling for multi-page fixed tables by removing headers that repeat on subsequent pages from the output.