

Text Table
Matches tables based on column coordinates in inches and returns their collated column contents. Anchor on the table title, or use a negative Offset Y parameter to enable anchoring on a column heading.
This method's advantages are:
- It's faster than other table methods because it doesn't use table recognition.
- It can extract unusally formatted tables that other table methods can't recognize.
Its disadvantage is that it's more limited than other table methods, because it relies on line alignment to find the table.
For alternatives to this method, see Table methods.
Parameters
Note: For additional parameters available for this method, see Global parameters for methods. The following table shows parameters most relevant to or specific to this method.
| key | value | description |
|---|---|---|
| id required | table | When you specify this method, you must also specify "type": "table" in the field's parameters. |
| columns required | array | An array of objects with the following parameters: - id (required): The id for the column in the extraction output.- minX (required): Specifies the left boundary of the column, in inches from the left edge of the page. To visually determine this coordinate, click a point in the document in the Sensible app, then drag to display inch dimensions. - maxX (required): Specifies the right boundary of the column, in inches from the left edge of the page. To visually determine this coordinate, click a point in the document in the Sensible app, then drag to display inch dimensions. - type: The table cell's type. For more information about types, see Types. - isRequired (default false): If true, Sensible omits a row if its cell is empty in this column. If false, Sensible returns nulls for empty cells in the row. Note that if you set this parameter to true for one column, Sensible omits the row for all columns, even if the row had content under other columns.Tip: You can define columns with overlapping coordinates, for example in order to output data in a single column as multiple columns. For more information, see the Examples section. |
| offsetY | number in inches. | Defines a starting point for recognizing a table, offset vertically from the anchor line's lower boundary. For example, if no table title precedes the table, then anchor instead on a column heading and use a negative Offset Y parameter to define a starting point above the table. |
| stop | Match object, array of Match objects, or number (inches) | (Recommended) Line to match or number in inches to stop table recognition:. - A Match object or array specifies to stop table recognition when Sensible matches text. - A number specifies the end of the table as the number of the inches offset along a Y-axis from the start of the table. Specify this parameter to prevent extracting non-table data and to enable recognizing a table that spans pages. If you don't specify this parameter, the table extends to the end of the page. Tip: In advanced use cases, you can use the syntax "stop": {"type": "last"} to recognize tables that span pages, but where there's no text you can use match on with the Stop parameter. This type of stop specifies to end the table at the end of the document or section. For example, use this type of stop to recognize tables in sections, where each table extends to the end of each section. |
| startOnRow | integer. default: 0 | Zero-indexed row number at which to start table extraction. For example, use this to exclude column headings from the output. As a stricter alternative, set the Is Required parameter on a column and set a type on the column (see example in Examples section). |
| stopOnRow | integer | Zero-indexed row number of the last table row to include in the table extraction. For example, specify "stopOnRow:2" to return the first 3 rows. Use negative numbers to specify a stop row that's offset from the last row of the table, where -1 specifies to include the last row. For example, specify "stopOnRow:-3" to return all rows except the last 2 rows of the table. |
| columnsRelativeToAnchor | boolean. Default: false | If true, specifies that the column coordinates minX and maxX are relative to the left edge of the anchor line, rather than to the left edge of the page. For example, use this parameter to recognize nested tables inside tables. |
| detectMultipleLinesPerRow | boolean or object default: false | If true, Sensible detects table cells containing newlines, rather than the default of treating each newline as a new row. In detail, Sensible detects that a cell contains newlines if the vertical gap between two lines is less than half the height of the second line. To troubleshoot multiline cell recognition, you can configure a Max Gap parameter that specifies the maximum allowable vertical gap in inches between newlines in a cell. For example, use this parameter to account for varying font sizes in a multi-line cell. Ensure that the gap you specify is smaller than the vertical gaps between rows. For example, if the vertical gaps between rows are 0.3 inches, specify 0.2 inches with the following syntax: "detectMultipleLinesPerRow": {"maxGap": 0.2 }For an example, see Example: Troubleshoot newlines. |
Examples
Example 1
The following example shows extracting two columns from a difficult-to-recognize table in the Sensible app:
- To prevent Sensible from returning unwanted term matches, the config specifies a Stop parameter.
- To handle cells with multiple lines, the config specifies true for the Detect Multiple Lines Per Row parameter.
- To exclude column headings, the config sets the Is Required parameter to true for column 4 and specifies the cell contents must be a currency.
Config
{
"fields": [
{
"id": "text_table_example",
"anchor": "outline",
"type": "table",
"method": {
"id": "textTable",
"detectMultipleLinesPerRow": true,
"columns": [
{
"id": "col2_limits",
"minX": 2.5,
"maxX": 4.1
},
{
"id": "col4_premiums",
"minX": 6,
"maxX": 7,
"type": "currency",
"isRequired": true
}
],
"stop": {
"type": "startsWith",
"text": "please"
}
}
}
]
}Example document
The following image shows the example document used with this example config:

| Example document | Download link |
|---|
Output
{
"text_table_example": {
"columns": [
{
"id": "col2_limits",
"values": [
{
"value": "$25,000 each person/$50,00 0 each accident",
"type": "string"
},
{
"value": "$20,000 each accident",
"type": "string"
},
{
"value": "...................",
"type": "string"
}
]
},
{
"id": "col4_premiums",
"values": [
{
"source": "$100",
"value": 100,
"unit": "$",
"type": "currency"
},
{
"source": "$10",
"value": 10,
"unit": "$",
"type": "currency"
},
{
"source": "$150",
"value": 150,
"unit": "$",
"type": "currency"
}
]
}
]
}
}Example 2
This example shows defining two columns with the same coordinates, in order to split data in the column into two columns determined by type. In this case, you output the issuing financial institution and the displayed account number as separate columns.
Config
{
"fields": [
{
"id": "split_column_into_two",
"anchor": "credit card",
"type": "table",
"method": {
"id": "textTable",
"detectMultipleLinesPerRow": true,
"columns": [
{
/* extract account number from 1st column
as its own column */
"id": "account_number",
"type": "number",
"minX": 1.0,
"maxX": 2.5
},
{
/* extract bank name from 1st column
as its on column */
"id": "institution_name",
"type": {
"id": "custom",
"pattern": "\\D+",
"type": "nonNumber"
},
"minX": 1.0,
"maxX": 2.5
},
],
"stop": {
"text": "computed",
"type": "includes"
}
}
}
]
}Example document
The following image shows the example document used with this example config:
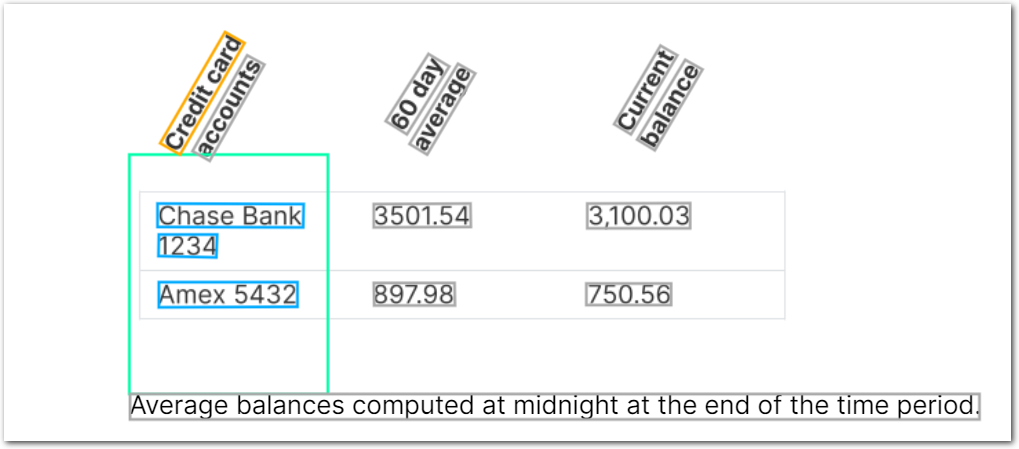
| Example document | Download link |
|---|
Output
{
"split_column_into_two": {
"columns": [
{
"id": "account_number",
"values": [
{
"source": "1234",
"value": 1234,
"type": "number"
},
{
"source": "5432",
"value": 5432,
"type": "number"
}
]
},
{
"id": "institution_name",
"values": [
{
"source": "Chase Bank ",
"value": "Chase Bank ",
"type": "custom",
"customType": "nonNumber"
},
{
"source": "Amex ",
"value": "Amex ",
"type": "custom",
"customType": "nonNumber"
}
]
}
]
}
}Example: Troubleshoot newlines
The following example shows handling newlines in a cell with varying font sizes using the Max Gap parameter.
Config
{
"fields": [
{
"id": "table_test",
"anchor": {
"match": {
"type": "includes",
"text": "disability"
}
},
"method": {
"id": "textTable",
/* ensures Sensible detects a small-font newline as part of a cell rather than as a new row. Configure a value that's a little larger than the vertical gap in inches between the smaller-font and the larger-font lines. */
"detectMultipleLinesPerRow": { "maxGap": 0.2 },
"stop": "for more details",
"columns": [
{
"id": "col1",
"minX": 1,
"maxX": 2.9
},
{
"id": "col2",
"minX": 2.9,
"maxX": 5.7
},
{
"id": "col3",
"minX": 5.7,
"maxX": 9
}
]
}
}
]
}
Example document
The following image shows the example document used with this example config:
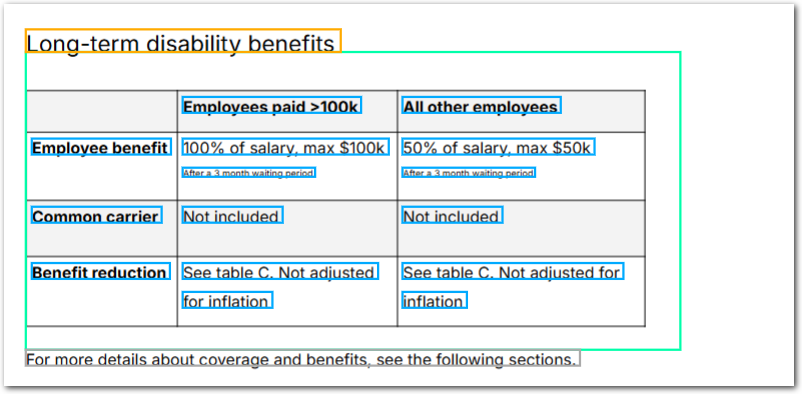
| Example document | Download link |
|---|
Output
{
"table_test": {
"columns": [
{
"id": "col1",
"values": [
null,
{
"value": "Employee benefit",
"type": "string"
},
{
"value": "Common carrier",
"type": "string"
},
{
"value": "Benefit reduction",
"type": "string"
}
]
},
{
"id": "col2",
"values": [
{
"value": "Employees paid 100k",
"type": "string"
},
{
"value": "100% of salary, max $100k After a 3 month waiting period",
"type": "string"
},
{
"value": "Not included",
"type": "string"
},
{
"value": "See table C. Not adjusted for inflation",
"type": "string"
}
]
},
{
"id": "col3",
"values": [
{
"value": "All other employees",
"type": "string"
},
{
"value": "50% of salary, max $50k After a 3 month waiting period",
"type": "string"
},
{
"value": "Not included",
"type": "string"
},
{
"value": "See table C. Not adjusted for inflation",
"type": "string"
}
]
}
]
}
}Notes
For alternatives to this method, see Table methods.
Updated 7 months ago