

October 2024
In the last month, we released a powerful new feature for configuring extraction from multi-document files ("portfolios") using large language models (LLMs). We also released the capability to specify a custom schema for your extracted document data instead of Sensible's default parsed_document schema. We improved the Sensible app user experience by enabling search for field keys and values in a new, compact view of extracted data. We also updated several model versions for LLM-based methods.
New feature: Segment subdocuments in bundled "portfolio" files using LLMs
Sensible supports extracting multiple documents from a single file (a "portfolio"). Now, you can segment the page ranges of the subdocuments in the file using large language model (LLM) based descriptions, instead of text matches ("fingerprints"). Use LLMs for easier and more flexible configuration of portfolio segmentation.
To enable LLM-based portfolio segmentation, navigate to a document type's Settings tab, then describe the documents in the type using natural language.
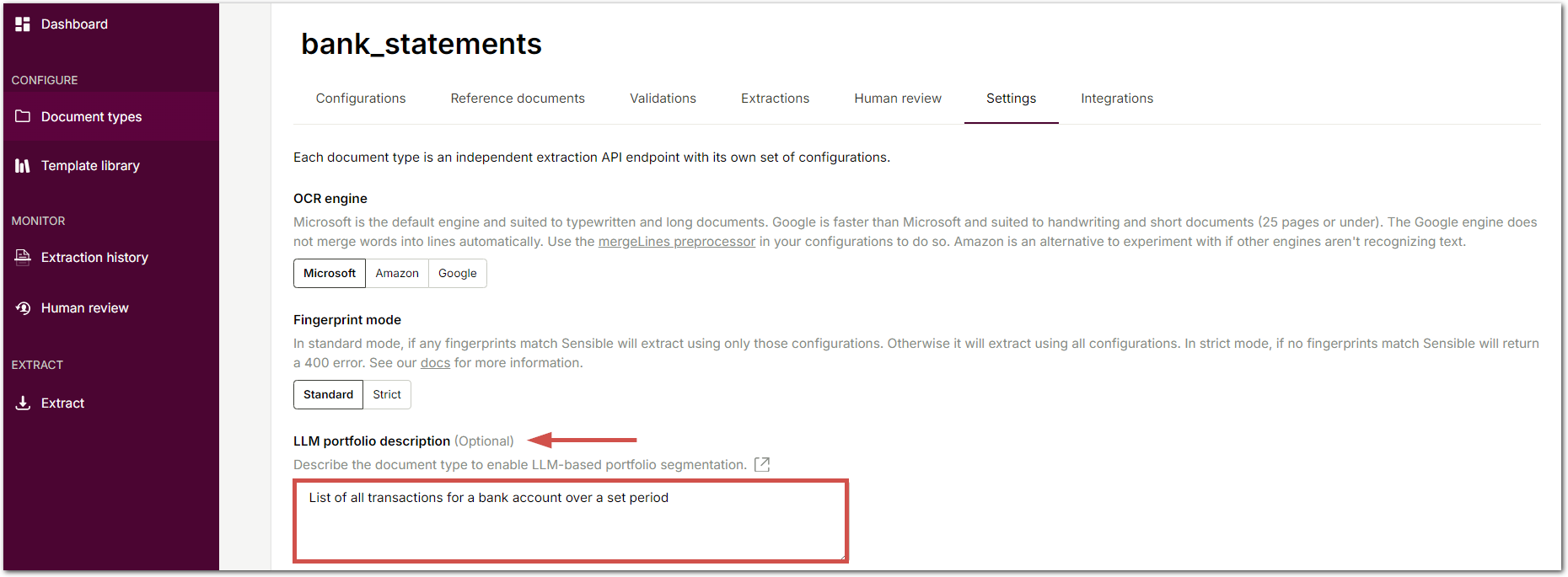 When you enable LLM mode for a portfolio extraction, Sensible identifies the page range for each document in the portfolio file based on your description and extracts it separately. You can then navigate through the extracted documents in the portfolio by page range:
When you enable LLM mode for a portfolio extraction, Sensible identifies the page range for each document in the portfolio file based on your description and extracts it separately. You can then navigate through the extracted documents in the portfolio by page range:
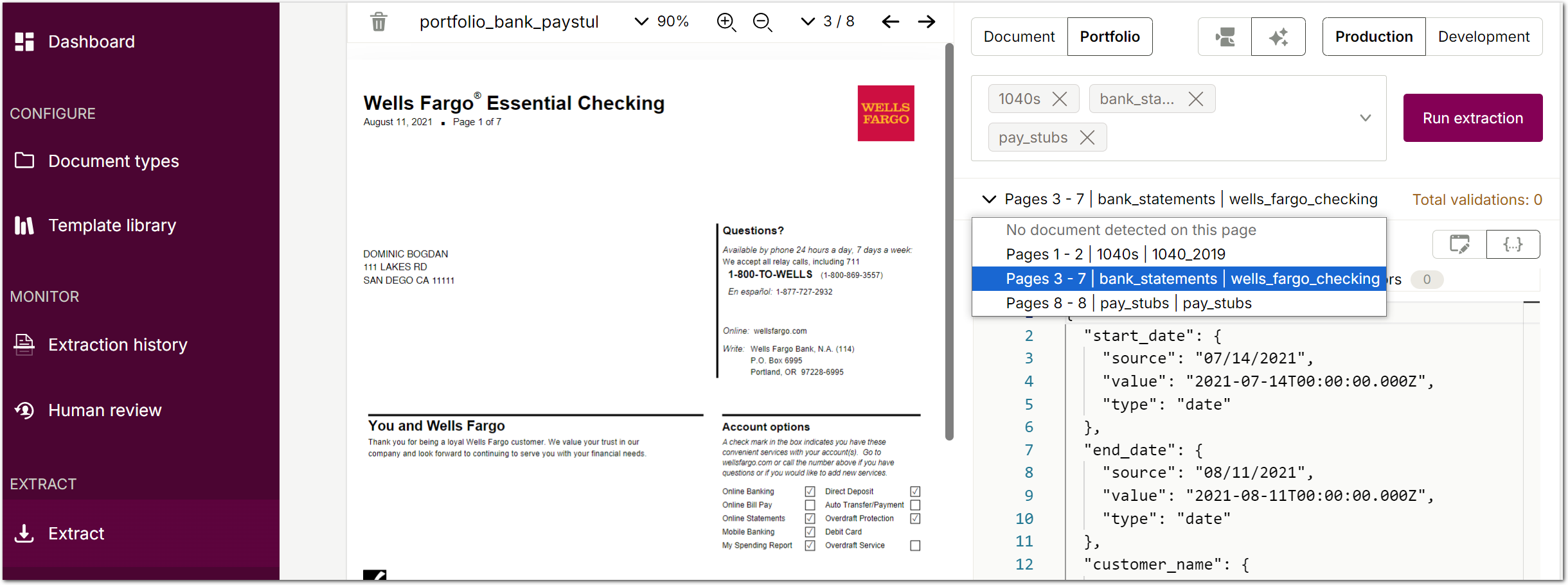
For more information, see Multi-document extractions.
New feature: Output custom extraction schemas
We've expanded our existing parsed_document schema manipulation features (such as the Custom Computation method) with a new postprocessor feature that lets you output a completely custom schema. For example, if your app or API consumes a pre-existing schema, you can now specify to output extracted document data in that schema using JsonLogic rules. Your custom schema is available in the postprocessorOutput object in the API extraction response or in the postprocessed tab of the Sensible app.
In detail, Sensible represents extracted document data as an array of fields in a parsed_document, each with value and type properties:
{
"parsed_document": {
"contract_date": {
"value": "2023-01-01T00:00:00.000Z",
"type": "date"
},
"customer_name": {
"type": "string",
"value": "John Smith"
}
}Using a postprocessor, you can transform the extracted data into a custom schema, for example:
{
"postprocessorOutput": {
"custom_object": {
"contract_date": "2023-01-01T00:00:00.000Z",
"customer_name": "John Smith"
}
}
}As part of the release, we've added new operations to our extended support for JsonLogic:
- You can build new objects in your custom schema using the Object operation.
- You can now flatten nested arrays to any recursive depth using the Flatten operation.
Improvement: Template library search features and organization
You can now browse the template library by industry type using the Use case button:
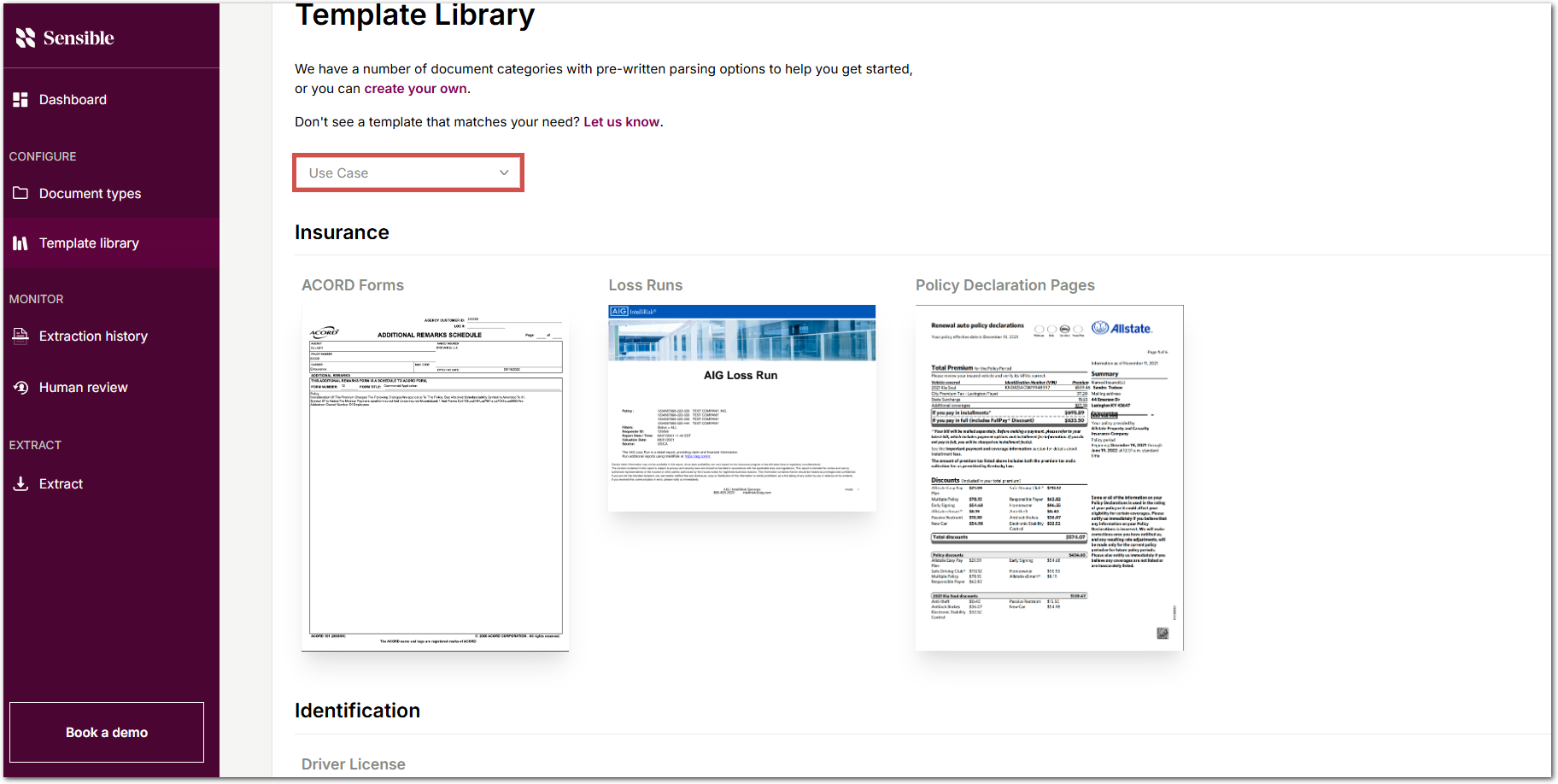
In addition, the library has been reorganized with the goal of creating more precise document types. For example, the tax_form document type has been split into new document types by form number.
UX improvement: Compact view and search for extracted fields and values
When you view an extraction in the Sensible app, you can now select a compact display for extracted fields and search by fields' keys and values. For fields with nested structures, you can search to any depth. Field search is available when you view an extraction's compact display in the JSON editor, in the Extraction History tab, in the Human Review tab, and in the Extract tab.
For example, the following image shows selecting UI mode to view the compact display of the extracted data in the JSON editor:
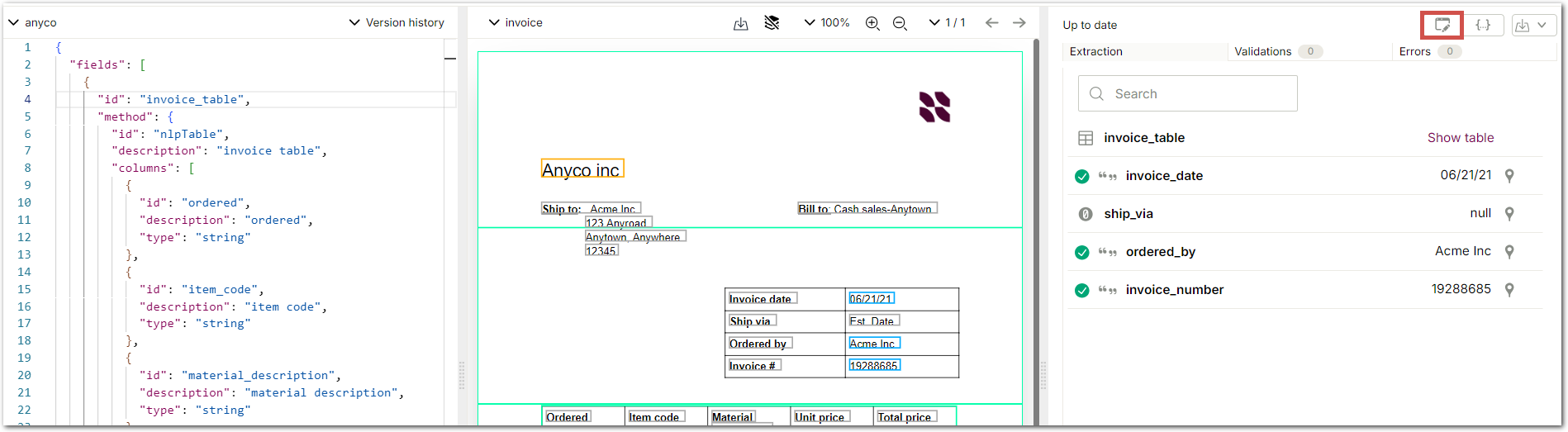
The following images show searching for a value in a table and getting back a nested result.
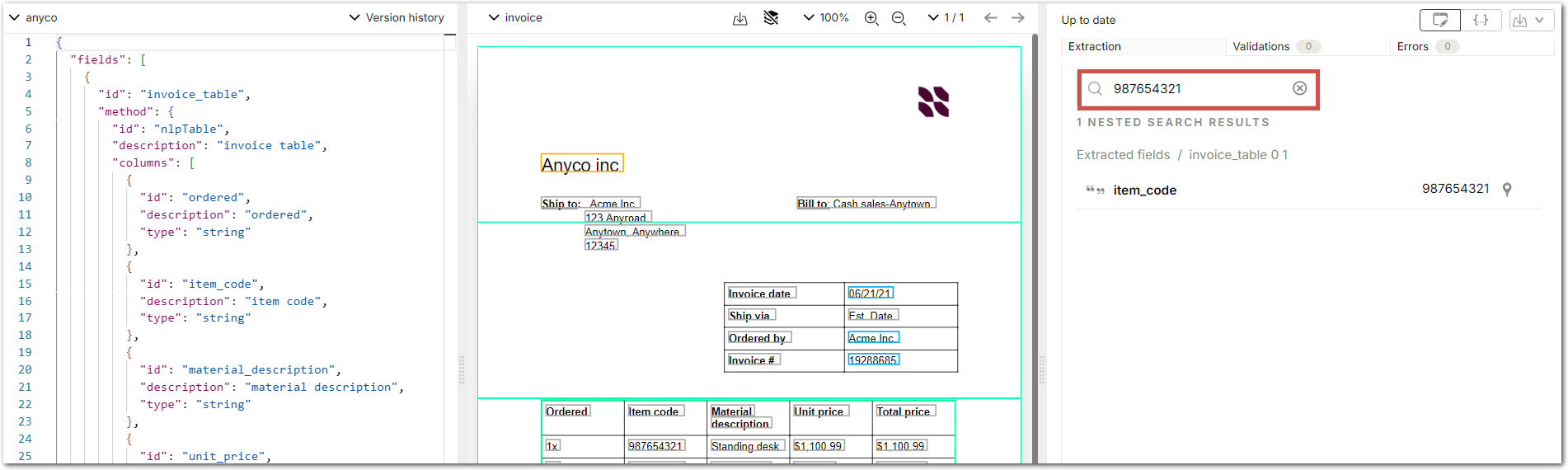
Click the location icon next to the search results to view the highlighted source in the PDF.
Improvement: Multimodal LLM data extraction from image file types
In April, we released support for extracting non-text image data from PDFs using a multimodal large language model (LLM). Now, we also support multimodal data extraction for JPG and PNG file types.
Improvement: LLM model version updates
The List method and NLP Table method have been updated to use GPT-4o by default.