

Multi-document extractions
Sensible supports extracting multiple documents from a single file (a "portfolio"). For example, for a portfolio file containing two invoices, a 1040 tax document, and a contract, Sensible can segment each document by its page range in the file, and return its extracted data separately.
Sensible recommends extracting each document in a portfolio using its own document type, so you can write validations for each type. For example, use an "income tax" doc type and an "invoice" doc type for the portfolio file in the previous example, rather than creating a "combined_tax_and_invoice" doc type.
To segment the subdocuments in a portfolio file, you have the following options:
| LLM-based | Text-based ("fingerprints") | |
|---|---|---|
| Segmentation method | Sensible prompts an LLM to segment the documents based on user-provided descriptions of the documents and their contents. For more information, see Document type descriptions. | Sensible finds user-configured text matches ("fingerprints") to segment documents. For more information, see fingerprints. |
| Granularity | at the document type level | at the config level |
Other tradeoffs between LLM and layout-based methods apply. For more tradeoffs, see Choosing an extraction approach.
Limitations
- For a list of supported portfolio file types, see Supported file types.
- Sensible doesn't support segmenting a document that start mid-page in a portfolio. It expects that the first page of each document in a portfolio starts at the top of a page.
Extracting from a portfolio
To extract from a portfolio, take the following steps:
- Enable segmentation with one of the following alternatives:
- LLM mode: In the document type's Settings tab, describe the document type in the Description field. For examples of descriptions, see LLM example and Document type descriptions.
- Fingerprint mode: Specify fingerprints in each config relevant to the portfolio file. Fingerprints test for text matches on first pages, last pages, and other page types. For an example of fingerprints, see Fingerprint example.
- Create an extraction request with one of the following alternatives:
-
Sensible app:
- On the Extract tab, upload the portfolio file.
- Click the Portfolio button and specify either fingerprint mode or LLM mode.
- Select the document types contained in the portfolio file.
- Click Extract.
-
API or SDK:
-
In a portfolio extraction API endpoint, specify the segmentation method and doc types, for example:
curl --location 'https://api.sensible.so/v0/extract_from_url?environment=production&document_name=portfolio_bank_paystub_tax' \ --header 'Content-Type: application/json' \ --header 'Authorization: ••••••' \ --data '{ "document_url":"https://raw.githubusercontent.com/sensible-hq/sensible-docs/v0/assets/pdfs/portfolio_bank_paystub_tax.pdf", "types": [ "bank_statements", "pay_stubs", "1040s" ], "segment_documents_with": "llm" }'For information about extracting from portfolios using the SDKs, see the SDK documentation.
-
The extraction response includes document extractions and their page ranges in the portfolio.
Examples
LLM example
The following example shows extracting three documents from a portfolio using LLMs to segment the documents. The portfolio contains a bank statement, a paystub, and a tax document. To try out the example, take the following steps:
-
Follow the steps in Out-of-the-box extractions to add support for the bank statements, 1040s, and pay stubs document types to your account.
Note: Each out-of-the-box document type comes preconfigured with a description in its Description field to enable LLM-based portfolio segmentation. The descriptions are as follows:
document type Description bank statements List of all transactions for a bank account over a set period pay stubs Historic payments to employees 1040s The standard individual income tax return form for U.S. taxpayers to report their annual income and calculate their federal tax liability. For example, the following image shows the description for the
bank_statementsdocument type: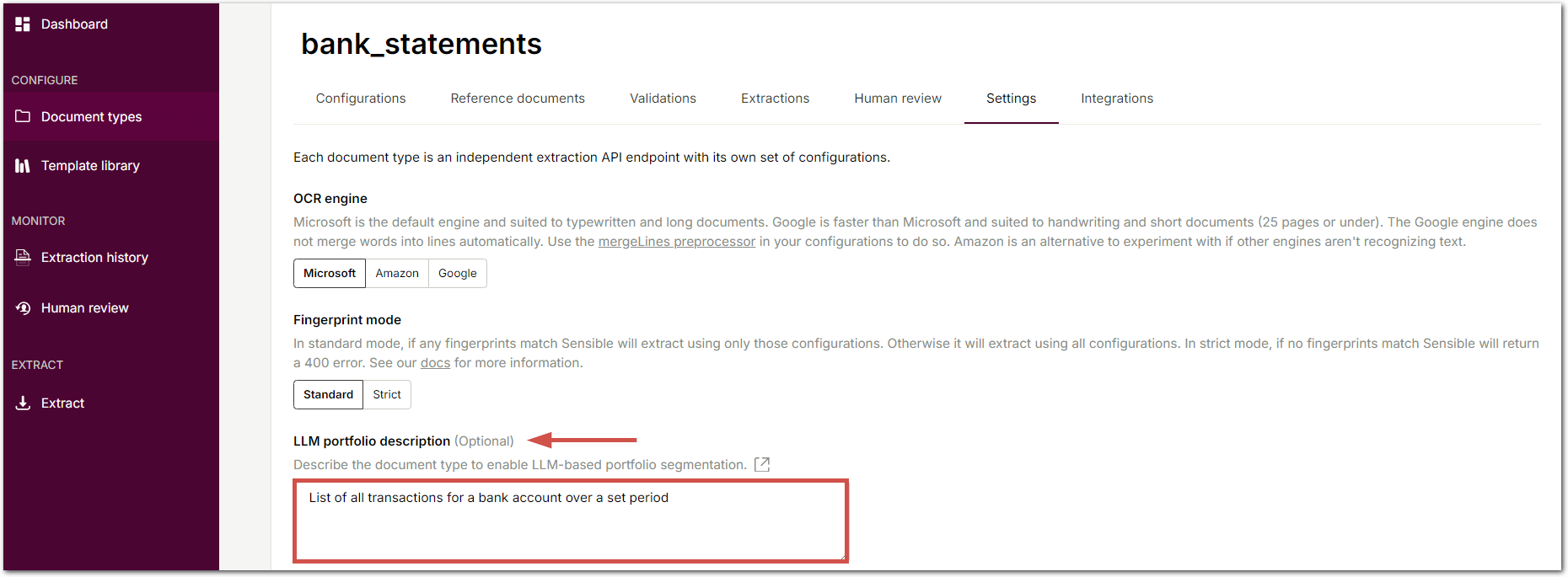
-
Download the following example document:
| Example document | Download link |
|---|
- In the Extract tab, upload the example document, select Portfolio, select LLM mode, and select the document types you just added support for:

- Click Extract. After the extraction completes, you can navigate through the extraction results in the portfolio using the dropdown:
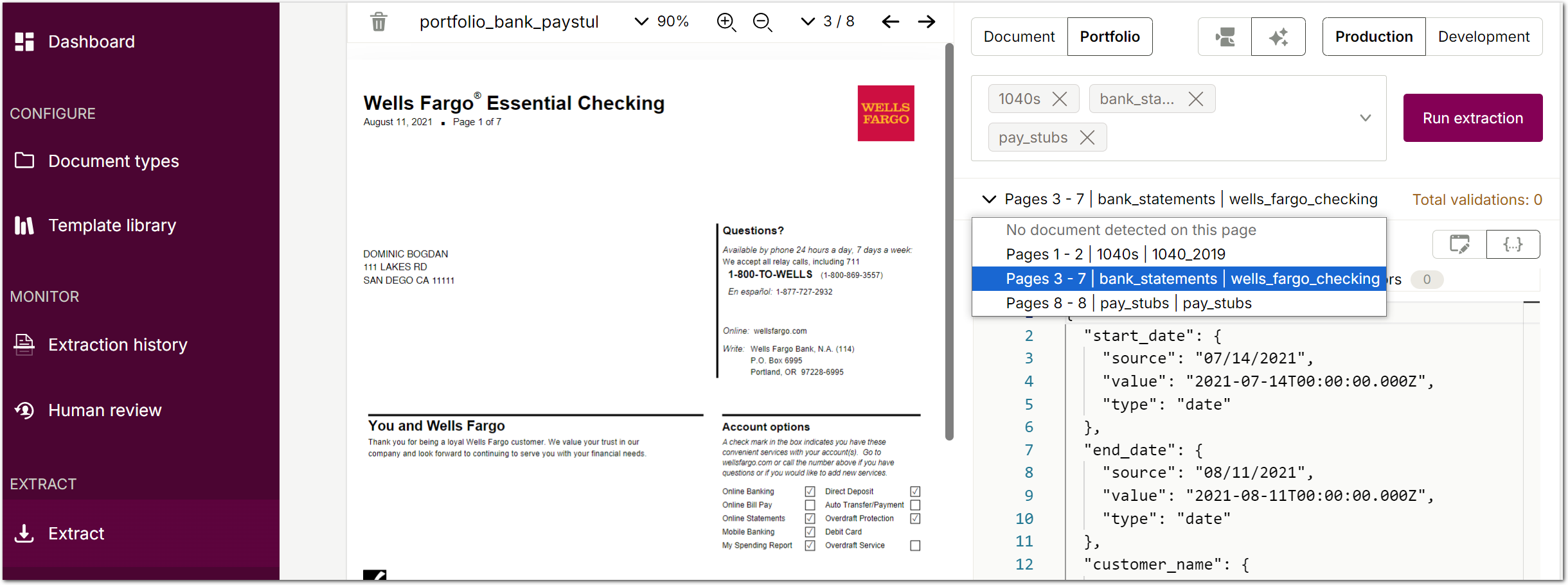
You should see results like the following:
Pages 1 - 2 | 1040s | 1040_2019
{
"year": {
"type": "string",
"value": "2020"
},
"filing_status.single": {
"type": "boolean",
"value": false
},
"filing_status.married_filing_jointly": {
"type": "boolean",
"value": true
},
"filing_status.married_filing_separately": {
"type": "boolean",
"value": false
},
"filing_status.head_of_household": {
"type": "boolean",
"value": false
},
"filing_status.qualifying_widow": {
"type": "boolean",
"value": false
},
"name": {
"type": "string",
"value": "Kevin Finnerty"
},
"ssn": {
"type": "string",
"value": "091-30-1116"
},
/* etc */Pages 3 - 7 | bank_statements | wells_fargo_checking
{
"start_date": {
"source": "07/14/2021",
"value": "2021-07-14T00:00:00.000Z",
"type": "date"
},
"end_date": {
"source": "08/11/2021",
"value": "2021-08-11T00:00:00.000Z",
"type": "date"
},
"customer_name": {
"type": "string",
"value": "DOMINIC BOGDAN"
},
"customer_address": {
"value": "111 LAKES RD\nSAN DEGO CA 11111",
"type": "address"
},
"account_summary_table": null,
/* etc */Pages 8 - 8 | pay_stubs | pay_stubs
{
"employer_name": {
"value": "Delta Airlines",
"type": "string",
"confidenceSignal": "confident_answer"
},
"employee_name": {
"value": "Clyde Drexler",
"type": "string",
"confidenceSignal": "confident_answer"
},
"employee_address": {
"value": "1123 Drive street",
"type": "string",
"confidenceSignal": "confident_answer"
},
"pay_date": null,
"pay_period_start_date": null,
"pay_period_end_date": null,
"net_pay": {
"source": "$2,076.28",
"value": 2076.28,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
},Fingerprint example
The following example shows extracting three one-page documents from a portfolio using fingerprints to segment the documents. The portfolio contains two car insurance quotes and one loss run.
Config
Document type 1
-
doc type: "auto_insurance_quotes"
-
config name: "anyco"
-
config content:
To the config in Getting started with layout-based extractions, append the following fingerprint:
"fingerprint": {
"tests": [
{
/* all these matches are unique to the first page. If a first page sometimes omits a match, specify alternatives
in the match array using the`any` match type. */
"page": "first",
"match": [
{
"text": "outline",
"type": "startsWith"
},
{
"text": "anycocarinsurance.com",
"type": "startsWith"
}
]
}
]
},Document type 2
-
doc type: "loss_run_reports"
-
config name: "acme"
-
config content:
To the config in the Example loss run topic, append the following fingerprint:
"fingerprint": {
"tests": [
{
/* all these matches are unique to the first page. If a first page sometimes omits a match, specify alternatives
in the match array using the`any` match type. */
"page": "first",
"match": [
{
"text": "any unprocessed claim",
"type": "startsWith"
}
]
}
]
},Example document
| Example document | Download link |
|---|
Output
For the preceding configurations, doc types, and example document portfolio, the following asynchronous request returns a list of document extractions:
- Make an extraction request. For example, through the API:
curl --request POST 'https://api.sensible.so/v0/extract_from_url/' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data-raw '{"document_url":"https://raw.githubusercontent.com/sensible-hq/sensible-docs/v0/assets/pdfs/portfolio.pdf",
"types":["auto_insurance_quotes","loss_run_reports"]}'- This request returns an extraction ID. Use it to retrieve the extractions by replacing YOUR_EXTRACTION_ID with the returned ID in the following example code:
curl --request GET 'https://api.sensible.so/v0/documents/YOUR_EXTRACTION_ID' \
--header 'Authorization: Bearer YOUR_API_KEY'The response contains extractions from three documents:
{
"id": "56a27285-9465-4781-82d1-3010bd5c589f",
"created": "2024-09-26T19:26:13.492Z",
"completed": "2024-09-26T19:26:21.691Z",
"status": "COMPLETE",
"types": [
"auto_insurance_quotes",
"loss_run_reports"
],
"environment": "production",
"documents": [
{
"documentType": "auto_insurance_quotes",
"configuration": "anyco",
"startPage": 0,
"endPage": 0,
"output": {
"parsedDocument": {
"bodily_injury_premium": {
"source": "$100",
"value": 100,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
},
"customer_service_phone": {
"value": "18001234567",
"type": "string",
"confidenceSignal": "confident_answer"
},
"policy_period": {
"type": "string",
"value": "April 14, 2021 - Oct 14, 2021"
},
"comprehensive_premium": {
"source": "$150",
"value": 150,
"unit": "$",
"type": "currency"
},
"policy_number": {
"type": "string",
"value": "123456789"
}
},
"configuration": "anyco",
"validations": [],
"coverage": 1,
"fileMetadata": {
"info": {
"modification_date": "2021-09-29T10:51:49.000-07:00"
}
},
"errors": [],
"needsReview": false,
"classificationSummary": [
{
"configuration": "anyco",
"score": {
"score": 5,
"coverage": 1,
"fieldsPresent": 5,
"penalties": 0
}
}
],
"validation_summary": {
"fields": 5,
"fields_present": 5,
"errors": 0,
"warnings": 0,
"skipped": 0
}
}
},
{
"documentType": "auto_insurance_quotes",
"configuration": "anyco",
"startPage": 1,
"endPage": 1,
"output": {
"parsedDocument": {
"bodily_injury_premium": {
"source": "$90",
"value": 90,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
},
"customer_service_phone": {
"value": "18001234567",
"type": "string",
"confidenceSignal": "confident_answer"
},
"policy_period": {
"type": "string",
"value": "May 20, 2021 - Nov 20,"
},
"comprehensive_premium": {
"source": "$130",
"value": 130,
"unit": "$",
"type": "currency"
},
"policy_number": {
"type": "string",
"value": "987654321"
}
},
"configuration": "anyco",
"validations": [],
"coverage": 1,
"fileMetadata": {
"info": {
"modification_date": "2021-09-29T10:51:49.000-07:00"
}
},
"errors": [],
"needsReview": false,
"classificationSummary": [
{
"configuration": "anyco",
"score": {
"score": 5,
"coverage": 1,
"fieldsPresent": 5,
"penalties": 0
}
}
],
"validation_summary": {
"fields": 5,
"fields_present": 5,
"errors": 0,
"warnings": 0,
"skipped": 0
}
}
},
{
"documentType": "loss_run_reports",
"configuration": "acme",
"startPage": 2,
"endPage": 2,
"output": {
"parsedDocument": {
"total_unprocessed_claims": {
"source": "5",
"value": 5,
"type": "number"
},
"monthly_total_unprocessed_claims": [
{
"type": "string",
"value": "Sept unprocessed claims: 2"
},
{
"type": "string",
"value": "Oct unprocessed claims: 1"
},
{
"type": "string",
"value": "Nov unprocessed claims: 2"
}
],
"unprocessed_sept_oct_claims_sections": [
{
"claim_number": {
"source": "1223456789",
"value": 1223456789,
"type": "number"
},
"phone_number": {
"type": "phoneNumber",
"source": "512 409 8765",
"value": "+15124098765"
},
"_everything_in_this_section": {
"type": "string",
"value": "Claim number: 1223456789 Claimant last name: Diaz Date of claim 09/15/2021 Phone number 512 409 8765"
}
},
{
"claim_number": {
"source": "9876543211",
"value": 9876543211,
"type": "number"
},
"phone_number": null,
"_everything_in_this_section": {
"type": "string",
"value": "Claim number: 9876543211 Claimant last name: Badawi Date of claim 09/08/2021 Phone number"
}
},
{
"claim_number": {
"source": "6785439210",
"value": 6785439210,
"type": "number"
},
"phone_number": {
"type": "phoneNumber",
"source": "505 238 8765",
"value": "+15052388765"
},
"_everything_in_this_section": {
"type": "string",
"value": "Claim number: 6785439210 Claimant last name: Levy Date of claim 10/03/2021 Phone number 505 238 8765"
}
}
]
},
"configuration": "acme",
"validations": [],
"coverage": 0.9090909090909091,
"fileMetadata": {
"info": {
"modification_date": "2021-09-29T10:51:49.000-07:00"
}
},
"errors": [],
"needsReview": false,
"classificationSummary": [
{
"configuration": "acme",
"score": {
"score": 10,
"coverage": 0.9090909090909091,
"fieldsPresent": 10,
"penalties": 0
}
}
],
"validation_summary": {
"fields": 7,
"fields_present": 7,
"errors": 0,
"warnings": 0,
"skipped": 0
}
}
}
],
"page_count": 3,
"validation_summary": {
"fields": 17,
"fields_present": 17,
"errors": 0,
"warnings": 0,
"skipped": 0
},
"download_url": "REDACTED",
"coverage": 0.9696969696969697,
"charged": 3,
"version_id": "2ZjsLpUxhkv4SqiHxugHKXNhbV_S1jah",
"reviewStatuses": [
null,
null,
null
]
}Updated about 2 months ago