December 2024
In the last month, Sensible upgraded its document-type classification endpoints to use large language model (LLM) completions instead of embeddings-based scorings, updated its GTP-4 vision model for better multimodal data extraction results, enabled uploading an unlimited number of reference documents to the web app, and added advanced functionality to several layout-based and computed field methods.
Improvement: Classify documents by type using LLMs
The classify endpoints now use LLM completions instead of embeddings-based scoring to classify documents by type. This change improves accuracy and makes configuration easier for users. Instead of uploading a variety of reference documents to improve classification performance, now you can optionally provide a brief description of the document type, e.g. "This type of document is a car rental agreement."
Improvement: GPT-4 Vision model version update
The Query Group method's Multimodal Engine, which enables you to extract data from non-text images, now uses GPT-4o mini.
UX improvement: Unlimited number of reference documents
For each document type you define in your account, you can now upload an unlimited number of reference documents.
Improvement: Zip computed field method
Sensible has improved the consistency of the Zip computed field method's behavior when you input a mix of arrays, tables, and sections. As a result you can now:
- Zip multiple tables together. The previous workaround was to first convert the tables to sections.
- Zip a mix of tables, section groups, and arrays. The previous behavior was to discard all non-section source IDs in a
sources_idlist that included a section, or discard non-table sources in asources_idlist that included table and array sources.
For more information, and for edge-case behavior retained for backward compatibility, see the Zip computed field method.
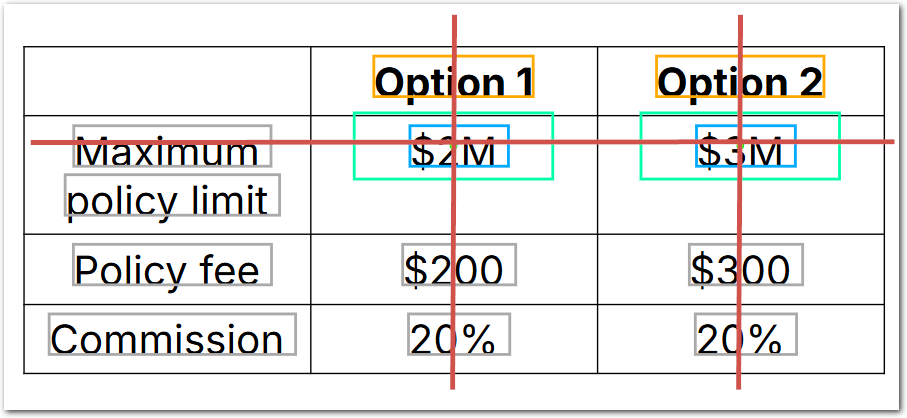
Improvement: Capture multiple intersections on a horizontal line
With the Intersection method's new Horizontal Anchor parameter, you can extract multiple intersections along a horizontal line, in addition to the existing behavior of capturing multiple intersections along a vertical line.
Improvement: API extraction response now includes configuration_version and content_type
configuration_version and content_typeThe extract endpoints now return the configuration_version of the configuration used to perform the extraction and the content_type of the document, for example, application/pdf.
UX improvement: Compact view of extraction history
The Extraction history tab now displays an improved, more compact view of past extractions by introducing new icons, including:
- a new extraction status icon next to the document name. If an extraction fails, you can click the icon to view the error message.
- a new review status icon next to the document name. If the extraction needs review, you can click the icon and open the review page.