

Query group
Extracts individual facts in a document, such as the date of an invoice, the liability limit of an insurance policy, or the destination address of a shipping container delivery.
- When you configure the Multimodal Engine parameter, you can extract from non-text data such as photographs, charts, or illustrations. For an example, see Example: Extract from images.
- When you configure the Source Fields parameter, you can chain LLM prompts together. In other words, you can extract data with one prompt, then apply further prompts to the extracted data.
Prompt Tips
Group prompts
Sensible recommends grouping queries together if they share context. Queries share context when data exists in the same region of a document, for example, on the same page.
For example, contact information can usually be found in the same location of a document:
Janelle Smith
New York City, NY
(123) 456-7890
[email protected] Combining queries for the custom name, location, phone number, and email into the same group will help you maximize the accuracy and speed of your extractions.
Phrase prompts
-
Try framing each query, or prompt, so that it has a single, short answer such as:
- "company address"
- "name of recipient"
- "document date"
-
Break up complex prompts into multiple prompts and chain them together.
For information about how this method works, see Notes.
Parameters
Note: For additional parameters available for this method, see Global parameters for methods. The following table only shows parameters most relevant to or specific to this method.
Note You can configure some of the following parameters in both the NLP preprocessor and in a field's method. If you configure both, the field's parameter overrides the NLP preprocessor's parameter.
Parameters
| key | value | description |
|---|---|---|
| method (required) | object | For this object's parameters, see the following table. |
| anchor | The Anchor parameter is optional for fields that use this method. If you specify an anchor and leave the Multimodal Engine unconfigured or configured with "region": "automatic" then:- Sensible ignores the anchor if it's present in the document. - Sensible returns nulls for the fields in this query group if the anchor isn't present in the document. If you configure the Multimodal Engine parameter's region manually, then an anchor is required, and Sensible creates the prompt's context relative to the anchor. |
Query group parameters
| key | value | description | interactions |
|---|---|---|---|
| id (required) | queryGroup | ||
| queries | array of objects | An array of query objects, where each extracts a single fact and outputs a single field. Each query contains the following parameters:id (required) - The ID for the extracted field. description (required) - A free-text question about information in the document. For example, "what's the policy period?" or "what's the client's first and last name?". For more information about how to write questions (or "prompts"), see Query Group extraction tips. | |
| CHAIN PROMPTS | |||
| source_ids | array of field IDs in the current config or object | If specified, prompts an LLM to extract data from another field's output. For example, if you extract a field _checking_transactions and specify it in this parameter, then Sensible searches for the answer to what is the largest transaction? in _checking_transactions, rather than searching the whole document to locate the context. Note that the _checking_transactions field must precede the largest_transaction field in the fields array in this example. For more information about this example, see Example: Transform fields.You can use a JavaScript-flavored regular expression to specify all field IDs that contain a pattern. For example, to specify all the field IDs containing the text wage extracted from a W-2 form, you can write "source_ids": { "pattern": ".*wage.*" }. For an example, see Example: Chain prompts with regex.When you use regex, Sensible populates the IDs in the array in the same order in which they're defined in the config. Sensible automatically expands your pattern to include string beginning and ending characters. For example, it expands the pattern ".*wage.*" to "^.*wage.*$".To extract repeating data, such as a list, specify the Source Ids parameter for the List method rather than for the Query Group method. For more information about chaining prompts, see Advanced LLM prompt configuration. The source field IDs can reference document data extracted from the current extraction, or caller-provided data such as data from a previous extraction or from a system of record. To supply caller-provided values, use the Extra Data method to create a field from a value in the request's extra_data object, then include that field ID in source_ids. | If you configure this parameter, then the following parameters aren't supported: - Anchor parameter in the field - Confidence Signals - Multimodal Engine parameter - Search By Summarization parameter - Page Range parameter |
| EXTRACT FROM IMAGES | |||
| multimodalEngine | object | Configure this parameter to: - Extract data from images embedded in a document, for example, photos, charts, or illustrations. - Troubleshoot extracting from complex text layouts, such as overlapping lines, lines between lines, and handwriting. For example, use this as an alternative to the Signature method, the Nearest Checkbox method, the OCR engine, and line preprocessors. This parameter sends an image of the document region containing the target data to a multimodal LLM so that you can ask questions about text and non-text images. This bypasses Sensible's OCR and direct-text extraction processes for the region. This parameter has the following parameters: - region: The document region to send as an image to the multimodal LLM. Configurable with the following options :- To automatically select top-scoring document chunks as the region, specify "region": "automatic". If you configure this option, then help Sensible locate the region by including queries in the group that target text lines near the image you want to extract from. - To manually specify a region, specify an anchor close to the region you want to capture. Specify the region's dimensions in inches relative to the anchor using the Region method's parameters, for example: "region": { "start": "below", "width": 8, "height": 1.2, "offsetX": -2.5,"offsetY": -0.25}- onlyImages: boolean. default: false. Configure this to troubleshoot image resolution. If set to true, Sensible sends only the images it detects overlapping the region and omits any lines overlapping the region. Sends the images at their original resolution. For an example, see Example: troubleshoot image resolution.For alternatives to the Multimodal parameter, see Image processing. | If you configure this parameter, then the Confidence Signals parameter isn't supported. |
| TROUBLESHOOT PROMPT | |||
| llmEngine | object | Configures the LLM model Sensible uses to extract data from context. Configure this parameter to troubleshoot situations in which Sensible correctly identifies the part of the document that contains the answers to your prompts, but the LLM's answer contains problems. For example, Sensible returns an LLM error because the answer isn't properly formatted, or the LLM doesn't follow instructions in your prompt. Contains the following parameters: provider: - If set to open-ai (default), Sensible uses an OpenAI model.- If set to anthropic, Sensible uses an Anthropic model.- If set to google, Sensible uses a Google model.For more information about models, see LLM models. | |
| confidenceSignals | boolean or "strict"or object default: true | If true, Sensible prompts the LLM to report any uncertainties it has about the accuracy of its response. For more information, see Qualifying LLM accuracy. If "strict", Sensible returns null for a field if its confidence signal is incorrect_answer.If an object, has engine and strict parameters, for example { "engine": "google", "strict": true } :- engine: the LLM provider to use for confidence signals. "open-ai", "anthropic", or "google". Default: "open-ai". For example, specify a provider to avoid output changes if Sensible updates the default provider. For more information, see LLM models.- strict: see previous description for behavior.If you specify an object, at least one property must be present. For example: { "engine": "open-ai" }. | Not supported if you specify the Multimodal Engine parameter or Source Ids parameter |
| FIND CONTEXT | |||
| searchBySummarization | boolean, or outline, or page (equivalent to true)default: false | (Recommended) Configure this to search for context using summaries of document chunks. If you set page, each page is a chunk. If you set outline, an LLM outlines the document, and each segment of the outline is a chunk.For more information, see Advanced LLM prompt configuration. This parameter is compatible with documents up to 1,280 pages long. For an example, see the Multicolumn preprocessor. | If you configure this parameter for a document 5 pages or under in length, Sensible submits the entire document as context, bypassing summarization. If you configure this parameter for a document over 5 pages long, then Sensible sets the Chunk Count parameter to 5 and ignores any configured value. |
| pageRange | object | Configures the possible page range for finding the context in the document. If specified, Sensible creates chunks in the page range and ignores other pages. For example, use this parameter to improve performance, or to avoid extracting unwanted data if your prompt has multiple candidate answers. Contains the following parameters: startPage: Zero-based index of the page at which Sensible starts creating chunks (inclusive). endPage: Zero-based index of the page at which Sensible stops creating chunks (exclusive). | Sensible ignores this parameter when searching for a field's anchor. If you want to exclude the field's anchor using a page range, use the Page Range preprocessor instead. |
| CONFIGURE CONTEXT SIZE | |||
| chunkCount | number. default: 5 | The number of top-scoring document chunks Sensible combines as context as part of the full prompt it submits to an LLM. |
Examples
Example: Extract from images
Config
The following example shows extracting structured data from real estate photographs embedded in an offering memorandum document using the Multimodal Engine parameter. It also shows extracting data from text.
{
"fields": [
{
"method": {
"id": "queryGroup",
"searchBySummarization": "page",
/* Use a multimodal LLM to extract data about a photograph embedded in a document,
for example the presence or absence of trees in the photo. */
"multimodalEngine": {
/* Sends the "context", or relevant document excerpt, as an image to the multimodal LLM.
If you configure "region":"automatic" for a non-text image,
then help Sensible locate the context by including queries
in the group that target text near the image */
"region": "automatic"
},
// multimodal egnine doesn't support confidence signals
"confidenceSignals": false,
"queries": [
{
"id": "trees_present",
"description": "are there trees on the property? respond true or false",
"type": "string"
},
{
"id": "multistory",
"description": "are the buildings multistory? return true or false",
"type": "string"
},
{
"id": "community_amenities",
"description": "give one example of a community amenity listed",
"type": "string"
},
{
"id": "exterior",
"description": "what is the exterior of the building made of (walls, not roof)?",
"type": "string"
}
]
}
}
]
}
Example document
The following image shows the example document used with this example config:

| Example document | Download link |
|---|
Output
{
"trees_present": {
"value": "true",
"type": "string"
},
"multistory": {
"value": "true",
"type": "string"
},
"community_amenities": {
"value": "Playground",
"type": "string"
},
"exterior": {
"value": "brick",
"type": "string"
}
}Example: Extract handwriting
The following example shows using a multimodal LLM to extract from a scanned document containing handwriting. For an alternate approach to extracting from this document, see also the Sort Lines example.
Config
{
"fields": [
{
/* use an anchor match to locate the
region, or relevant document excerpt,
to send as an image to the multimodal LLM */
"anchor": "ownership information",
"method": {
"id": "queryGroup",
/* Use a multimodal LLM to troubleshoot
problems with Sensible's default OCR engine and line merging.
This 1-step option avoids advanced configuration of the defaults.
*/
"multimodalEngine": {
/* manually specify the region's dimensions in inches
relative to the anchor. Use the green region overlay in the
rendered PDF to determine the dimensions */
"region": {
"start": "below",
"width": 8,
"height": 6,
"offsetX": -1.5,
"offsetY": 0.05
}
},
"queries": [
{
"id": "ownership_type",
"description": "What is type of ownership?",
"type": "string"
},
{
"id": "owner_name",
"description": "What is the full name of the owner?",
"type": "string"
}
]
}
},
/* Without the multimodal LLM engine, Sensible's default
OCR, line sorting, and line merging options result
in incorrect answers. */
{
"method": {
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
{
"id": "ownership_type_no_multimodal",
"description": "What is the type of ownership?",
"type": "string"
},
{
"id": "owner_name_no_multimodal",
"description": "What is the full name of the owner?",
"type": "string"
}
]
}
}
],
}Example document
The following image shows the example document used with this example config:
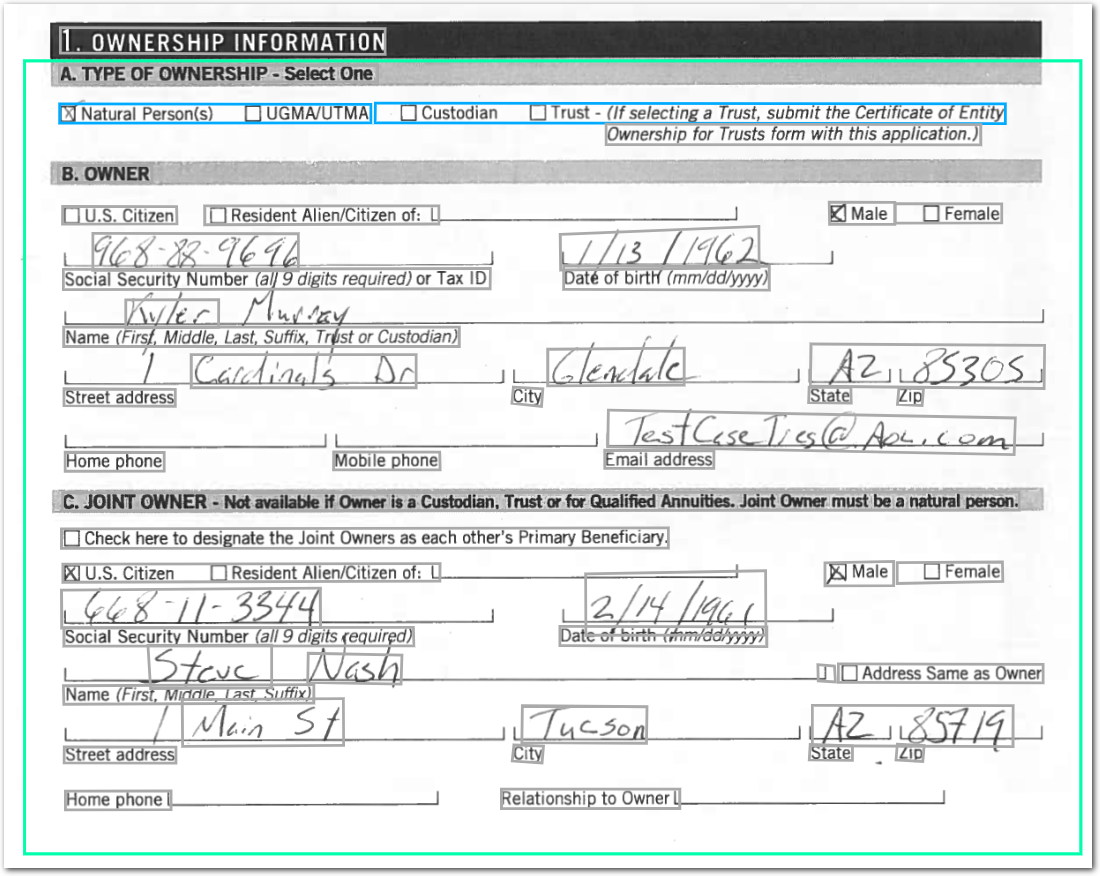
| Example document | Download link |
|---|
Output
{
"ownership_type": {
"value": "Natural Person(s)",
"type": "string",
"confidenceSignal": "not_supported"
},
"owner_name": {
"value": "Kyler Murray",
"type": "string",
"confidenceSignal": "not_supported"
},
"ownership_type_no_multimodal": {
"value": "Natural Person(s) UGMA/UTMACustodian Trust - (If selecting a Trust, submit the Certificate of Entity Ownership for Trusts form with this application.)",
"type": "string",
"confidenceSignal": "confident_answer"
},
"owner_name_no_multimodal": {
"value": "Mylic",
"type": "string",
"confidenceSignal": "answer_may_be_incomplete"
}
}Example: Extract from lease
The following example shows using the Query Group method to extract information from a lease.
Config
{
"fields": [
{
"method": {
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
{
"id": "tenancy_terms_start",
"description": "tenancy terms start date",
"type": "date"
},
{
"id": "tenancy_terms_end",
"description": "tenancy terms end date",
"type": "date"
},
{
"id": "notice_days_tenant_break",
"description": "number of days notice for tenant must give to terminate lease",
"type": "string"
},
{
"id": "monthly_rents_dollars",
"description": "monthly rents in dollars",
"type": "currency"
},
{
"id": "rent_due_in_month",
"description": "when is the rent due in the month",
"type": "string"
},
{
"id": "grace_period_rent_due",
"description": "grace period for the rent due",
"type": "string"
},
{
"id": "late_fee_amounts",
"description": "late fee amount",
"type": "string"
},
{
"id": "fee_returned_checks",
"description": "fee in dollars for returned checks or rejected payments",
"type": "currency"
}
]
}
}
]
}Example document
The following image shows the example document used with this example config:

| Example document | Download link |
|---|
Output
{
"tenancy_terms_start": {
"source": "01/01/2022",
"value": "2022-01-01T00:00:00.000Z",
"type": "date",
"confidenceSignal": "confident_answer"
},
"tenancy_terms_end": {
"source": "12/31/2023",
"value": "2023-12-31T00:00:00.000Z",
"type": "date",
"confidenceSignal": "confident_answer"
},
"notice_days_tenant_break": {
"value": "30 days",
"type": "string",
"confidenceSignal": "confident_answer"
},
"monthly_rents_dollars": {
"source": "895.00",
"value": 895,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
},
"rent_due_in_month": {
"value": "on or before the 1st day of each month",
"type": "string",
"confidenceSignal": "confident_answer"
},
"grace_period_rent_due": {
"value": "5 days",
"type": "string",
"confidenceSignal": "confident_answer"
},
"late_fee_amounts": {
"value": "10 Percent of Recurring Rent Only",
"type": "string",
"confidenceSignal": "confident_answer"
},
"fee_returned_checks": {
"source": "$50",
"value": 50,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
}
}Example: Extract from pie charts
For an example of extracting visual data from a pie chart using the Multimodal Engine parameter, see the example in the Multicolumn preprocessor topic.
Example: Extract data from other fields
The following example shows how to chain prompts. It restricts an LLM's context for a prompt to another field's output.
Config
{
"fields": [
{
/* extract the transactions table ("account activity") */
"id": "_transactions",
"type": "table",
"method": {
"id": "list",
"searchBySummarization": "page",
"description": "transactions detail",
"properties": [
{
"id": "transaction_date",
"description": "date of transaction"
},
{
"id": "merchant_name",
"description": "merchant"
},
{
"id": "transaction_description",
"description": "description or category of transaction"
},
{
"id": "transaction_amount",
"description": "amount",
"type": "accountingCurrency",
"isRequired": true
}
]
}
},
{
"method": {
"id": "queryGroup",
"source_ids": [
/* restrict queries to data in _transactions field */
"_transactions"
],
"confidenceSignals": false,
"queries": [
{
// correct answer is "Payment Thank You - Web"
"id": "freq_merchant_chained_query",
"type": "string",
"description": "What is the most frequent merchant?"
},
{
// correct answer is 1287.37
"id": "max_transaction_amount_chained_query",
"description": "what is the maximum transaction amount?"
}
]
}
},
{
"method": {
"id": "queryGroup",
"searchBySummarization": "page",
"confidenceSignals": false,
/* for contrast, if you query the whole document rather than the
transactions table, you get incorrect answers */
"queries": [
{
// correct answer is "Payment Thank You - Web"
"id": "freq_merchant",
"type": "string",
"description": "What is the most frequent merchant?"
},
{
// correct answer is 1287.37
"id": "max_transaction_amount",
"description": "what is the maximum transaction amount?"
}
]
}
},
{
"id": "clean",
"method": {
"id": "suppressOutput",
"source_ids": [
"_transactions",
]
}
}
]
}Example document
The following image shows the example document used with this example config:
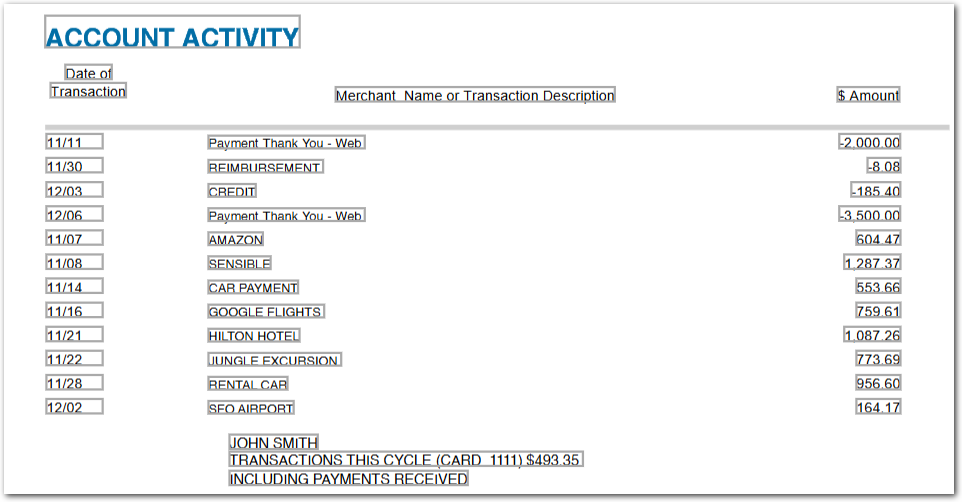
| Example document | Download link |
|---|
Output
{
"freq_merchant_chained_query": {
"value": "Payment Thank You - Web",
"type": "string"
},
"max_transaction_amount_chained_query": {
"value": "1287.37",
"type": "string"
},
"freq_merchant": null,
"max_transaction_amount": {
"value": "$6,186.83",
"type": "string"
}
}Example: Troubleshoot image resolution
The following example shows troubleshooting image resolution for a utility bill bar graph that uses a small font size.
Config
{
"fields": [
{
/* send the region under the heading
'energy use history' as an image to the LLM */
"anchor": {
"match": {
"text": "energy use history",
"type": "includes"
}
},
"method": {
"id": "queryGroup",
"confidenceSignals": false,
"multimodalEngine": {
"region": {
"start": "left",
"offsetX": -0.1,
"offsetY": 0.3,
"width": 4,
"height": 1.3
},
/* send the bar graph image in the region
to the LLM at its original resolution
and discard any non-image text ("lines") in the region */
"onlyImages": true
},
"queries": [
{
"id": "bar_graph_original_resolution",
"description": "This is a chart that shows electrical usage per month. I need the value of kwh for each month. Return all the values as comma-separated string. This is only one question",
"type": "string"
}
]
}
},
{
"anchor": {
"match": {
"text": "energy use history",
"type": "includes"
}
},
"method": {
"id": "queryGroup",
"confidenceSignals": false,
"multimodalEngine": {
"region": {
"start": "left",
"offsetX": -0.1,
"offsetY": 0.3,
"width": 4,
"height": 1.3
},
"onlyImages": false
},
"queries": [
{
/* when onlyImages is false, the output is inaccurate */
"id": "bar_graph_sensible_resolution",
"description": "This is a chart that shows electrical usage per month. I need the value of kwh for each month. Return all the values as comma-separated string. This is only one question",
"type": "string"
}
]
}
},
{
/* field that demonstrates that Sensible strips text when onlyImages:true */
"anchor": {
"match": {
"text": "energy use snapshot",
"type": "includes"
}
},
"method": {
"id": "queryGroup",
"multimodalEngine": {
"region": {
"start": "left",
"offsetX": -0.1,
"offsetY": 0.3,
"width": 2.0,
"height": 1.3
},
"onlyImages": true
},
"queries": [
{
/* this query returns null because
onlyImages captures images, not lines.
set onlyImages: false to get the
expected output of $2.46 */
"id": "daily_cost",
"description": "what's the average daily cost",
"type": "string"
}
]
}
}
]
}
Example document
The following image shows the example document used with this example config:
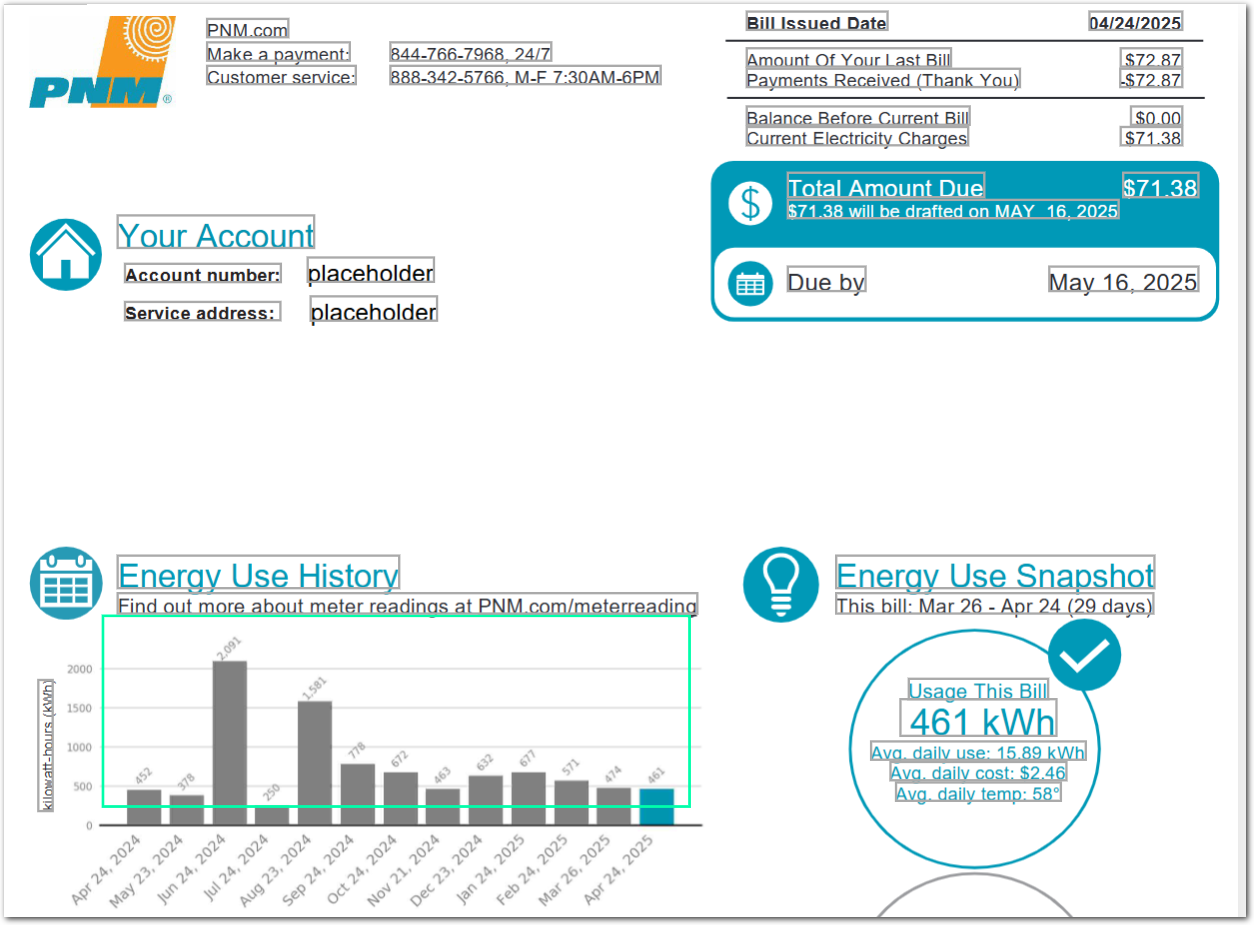
| Example document | Download link |
|---|
Output
{
"bar_graph_original_resolution": {
"value": "452,378,250,2091,1581,778,672,463,632,677,571,474,461",
"type": "string"
},
"bar_graph_sensible_resolution": {
"value": "2091,1581,778,672,463,632,677,571,474,461",
"type": "string"
},
"daily_cost": null
}Example: Chain prompts with regex
The following example shows how to chain prompts using a regular expression. The example extracts wages fields from a W-2 tax form, then searches for all extracted field IDs that contain the string "wages" to sum their values.
Config
{
"fields": [
{
"method": {
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
/* extract all wages fields */
{
"id": "wages_tips_compensation",
"description": "Total wages, tips, and other compensation"
},
{
"id": "fed_income tax_withheld",
"description": "federal income tax withheld"
},
{
"id": "social_security_wages",
"description": "Social security wages"
},
{
"id": "medicare_wages",
"description": "medicare wages and tips"
},
{
"id": "state_wages",
"description": "state wages and tips"
}
]
}
},
{
"method": {
"id": "queryGroup",
/* Regular expression to find all
source IDs that include the string "wage".
Sensible populates the IDs in the source array in the same order in which they're defined in the config, and the field containing the `source_ids` regex must follow the sources in the `fields` array.
Sensible automatically expands your pattern to include string beginning and ending characters. For example, it expands the pattern `".*wage.*"` to `"^.*wage.*$"` */
"source_ids": { "pattern": ".*wage.*" },
"confidenceSignals": false,
"queries": [
{
/* chain prompts: calculate sums based
on the extracted wages fields */
"id": "sum_wages",
"type": "string",
"description": "sum of all wages"
},
{
"id": "sum_wages_minus_medicare",
"type": "string",
"description": "sum of all wages excluding medicare wages and tips"
}
]
}
}
]
}
Example document
The following image shows the example document used with this example config:

| Example document | Download link |
|---|
Output
{
"wages_tips_compensation": {
"value": "69780.46",
"type": "string",
"confidenceSignal": "confident_answer"
},
"fed_income tax_withheld": {
"value": "5393.17",
"type": "string",
"confidenceSignal": "confident_answer"
},
"social_security_wages": {
"value": "77447.24",
"type": "string",
"confidenceSignal": "confident_answer"
},
"medicare_wages": {
"value": "22474.24",
"type": "string",
"confidenceSignal": "confident_answer"
},
"state_wages": {
"value": "68780.48",
"type": "string",
"confidenceSignal": "confident_answer"
},
"sum_wages": {
"value": "238482.42",
"type": "string"
},
"sum_wages_minus_medicare": {
"value": "216008.18",
"type": "string"
}
}Notes
For an overview of this method's default approach to locating context, see the following steps.
For alternate approaches, see Advanced LLM prompt configuration.
How it works by default
-
Sensible finds the chunks of the document that most likely contain your target data:
- Sensible splits the document into equal-sized chunks.
- Sensible scores each chunk by its similarity to either the concatenated Description parameters for the queries in the group. Sensible scores each chunk.
-
Sensible selects a number of the top-scoring chunks and combines them into "context". The chunks can be non-consecutive in the document. If the chunks exceed the LLM's token limit, Sensible automatically reduces the chunk count until the context meets the token limit.
-
Sensible creates a full prompt for the LLM that includes the chunks, page-hinting data, and your Description parameters. For more information about the full prompt, see Advanced LLM prompt configuration.
Updated about 1 month ago