

July 2025
In the last month, Sensible released several major new features. We introduced email-driven document extraction for automated processing of email attachments, significantly expanded our auto-generated extraction schemas to handle larger and more complex documents, and added new troubleshooting capabilities for multimodal extractions. We also added several advanced configuration options and deprecated some older LLM configuration options.
New feature: Email document extraction
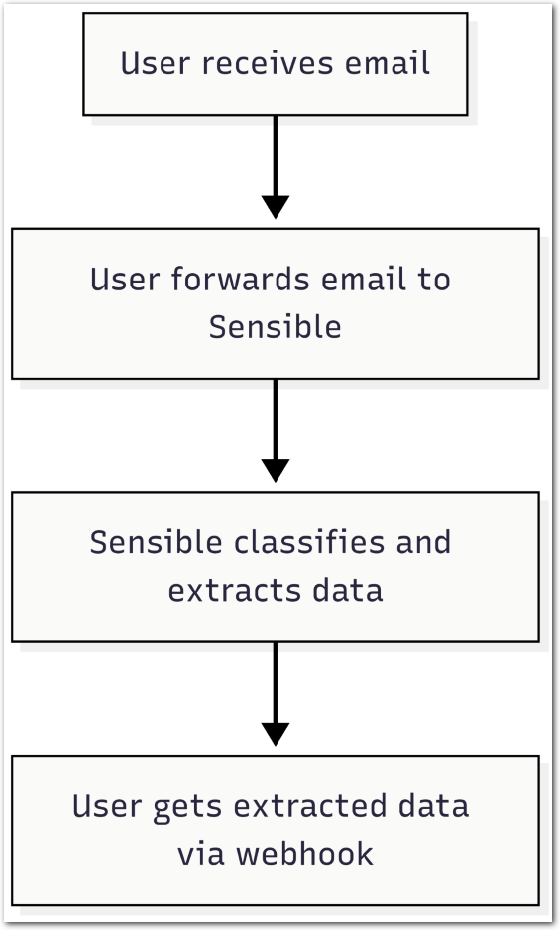
Sensible added support for automated extraction from email documents. Users can now forward emails with attachments to Sensible for automatic classification and data extraction. Key features include:
- LLM-based attachment classification against specified document types
- Support for multiple attachments per email
- Optional email body extraction
- Webhook delivery of extraction results with metadata and download links
See Getting started with email extraction for more information.
Improvement: Smarter auto-generated extraction schemas
We've significantly expanded the scope of our existing auto-extraction capabilities to handle larger, more complex documents. When you upload a document sample to a new document type in Sensible, we automatically extract data from the document and generate a reusable extraction schema, or "config", with zero configuration on your part. Sensible uses LLMs to identify the most relevant data points in your document.
Our enhanced auto-extraction now includes:
- Extended page count: Auto-extract from up to the first 50 pages of a document (expanded from 2 pages)
- Multiple extraction methods: Sensible generates an extraction schema that outputs both individual facts and lists using the Query Group and List methods (previously included only the Query Group method)
- Increased field capacity: Auto-extract up to 60 fields total (up from about 10 total)
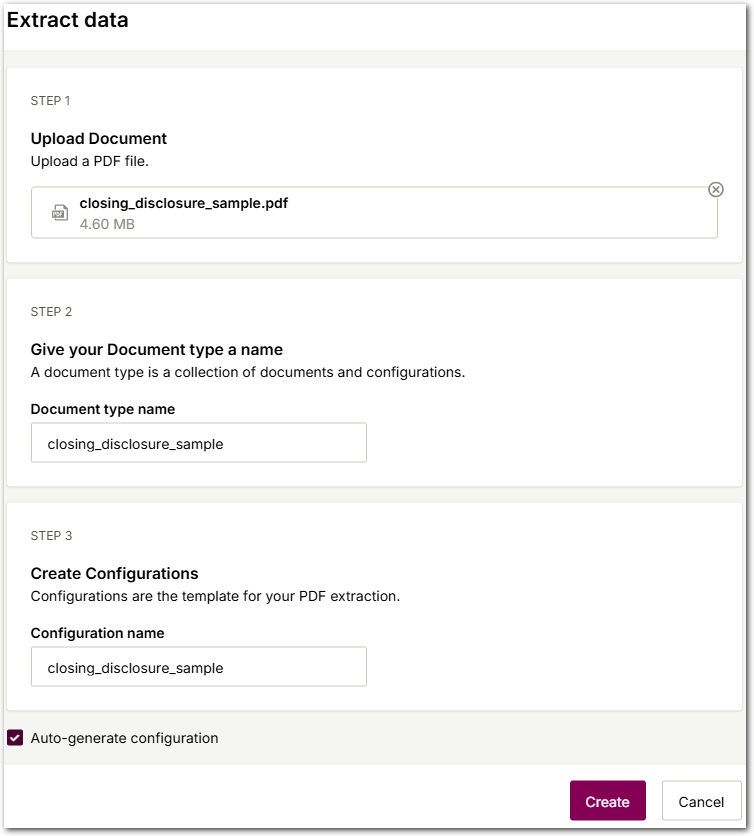
To use this feature, ensure that the Auto-generate checkbox is selected when you create a new document type:
You should see an auto-generated config and auto-extracted data like the following:

Improvement: Troubleshoot image resolution for multimodal extractions
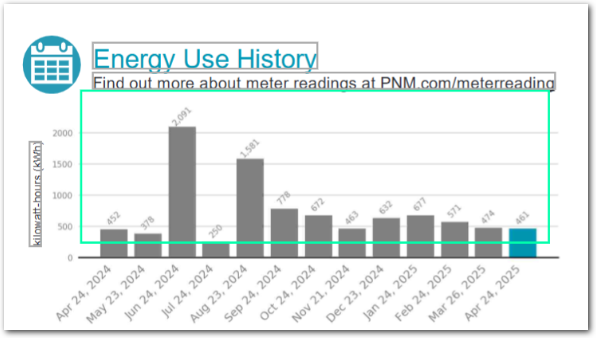
For images with small fonts or other resolution challenges, you can now use the Only Images parameter to troubleshoot multimodal data extractions. This option is available for the Query Group's Multimodal Engine parameter. For example, for the small-font numbers in the following bar chart, set the Images Only parameter to send the bar chart at its original resolution to the LLM. Note that setting this parameter means that Sensible only sends detected images in the document region it sends to the LLM as context; it strips out any non-image text. For more information, see Query Group.
Deprecation: Low-level LLM parameters
As Sensible continues to add higher-level LLM configuration parameters, we're deprecating some older, lower-level configuration parameters. The following parameters are now deprecated:
- Chunk Size
- Chunk Overlap Percentage
- Chunk Scoring Text
- Context Description
- Page Hinting
Improvement: Configuration for large spreadsheet extraction
Sensible offers new configuration options for extracting from large spreadsheets with tens of thousands of rows. With the Cell Row field type's new Stop and Header Columns Count parameters, you can specify to stop extraction at a matching row and specify multiple header rows, respectively. For more information, see Spreadsheet extraction.
New feature: Advanced JsonLogic sorting operation
In addition to the existing JsonLogic operators for transforming extracted data, Sensible released the new Sort By operator. This allows you to sort an array of objects in ascending alphanumeric order by the specified key. For more information, see Sort By.