

Choosing an extraction approach
As you scale up and encounter document complexity, you can optimize extraction performance by choosing between large language model (LLM)-based or layout-based extraction methods.
See the following diagram for an overview of when to use layout-based or LLM-based methods:
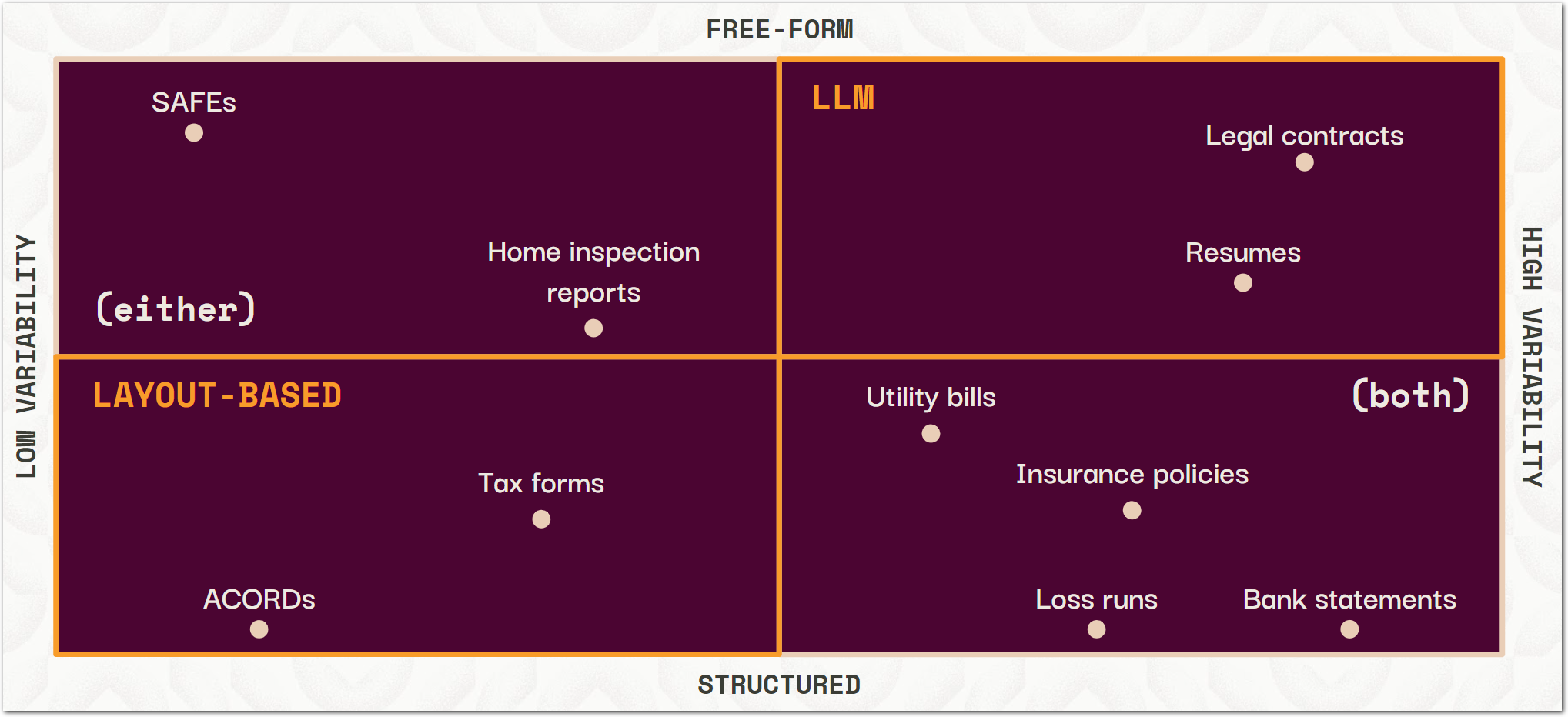
Sensible recommends using LLM prompts for free-form, highly variable documents, and layout-based, or "rule-based" queries for structured, less-variable documents. In cases where either strategy works, Sensible recommends layout-based queries for the sake of fast performance and deterministic output. You can mix and match strategies since they're both part of Sensible's query language, SenseML. For example, you can fall back between layout- and LLM-based queries for the same document.
See the following table to learn more about extraction strategies:
| extraction method | get started | notes |
|---|---|---|
| LLMs | Getting started | Prompt an LLM by describing the data you want to extract. |
| layout-based | Getting started with layout-based extractions | To extract from complex document layouts, author layout-based queries. |
| out-of-the-box | Getting started with out-of-the-box extractions | Sensible provides out-of-the-box extraction configurations for common business forms. Use Sensible's pre-built, open-source configuration library to extract key information from tax documents such as 1040s, major carrier insurance declaration pages, and other documents. Then tweak the pre-built configurations for your custom data needs. |
See the following table for an overview of the pros and cons of LLMs versus layout-based extraction:
| LLM-based | layout-based | |
|---|---|---|
| Technical expertise required | For nontechnical users. Describe what you want to extract in a prompt to an LLM. For example, "the policy period" or "total amount invoiced". | Offers powerful extraction configuration for technical users based on spatial layout. For example, grab the text in a rectangular region relative to the word "Addendums" |
| Workflow automation | Suited to workflows that include human review or that are fault-tolerant. | Suited to automated workflows that require predictable results and validation. |
| Document variability | Suited to documents that are unstructured or that have a large number of layout variations or revisions. | Suited to structured documents with a finite number of variations, where you know the layout of the document in advance. |
| Deterministic | No | Yes. Find the information in the document using anchoring text and layout data. |
| Handles repeating layouts | Use List method. | Use sections for highly complex repeating substructures, for example, loss runs. |
| Handles non-text images (photos, illustrations, charts, etc) | To extract data about images ("is the building in this picture multistory?", use Query Group method with the Multimodal Engine parameter configured | No |
| Performance | Data extraction takes a few seconds for each LLM-based method. | Offers faster performance in general. For more information, see Optimizing extraction performance. |
Updated 7 days ago