

Getting started with layout-based extractions
In this tutorial, you'll learn to extract data from a set of similar documents using Sensible's query language, SenseML. You'll write JSON-formatted SenseML to tell Sensible about which data to extract from an example document, using what you know about the layout of the document.
You can then save your descriptions as a "config." Publish your config to automate extracting from similar documents.
Use this tutorial if you want a guided tour of SenseML's layout-based concepts and the Sensible app. Or see the following links:
-
Layout-based methods are for advanced config authoring. For a simpler authoring experience, use LLM-based methods. For more information about layout-based versus LLM-based extraction methods, see Choosing extraction strategy. For getting started with LLMs, see Getting started.
-
If you instead want to explore without much explanation, then sign up for an account and check out our interactive in-app tutorials.
-
If you want a quick "hello world" API response, see the API quickstart.
Get structured data from an auto insurance quote
Let's get started with SenseML!
If you can write basic SQL queries, you can write SenseML queries. SenseML shields you from the underlying complexities of PDFs, so you can write queries that are visually and logically clear to a human programmer.
In this tutorial, you'll:
- Write a collection of queries ( a "config") to extract structured data from an example auto insurance document
- Learn how the config works, including key concepts like lines, anchors, and methods
- Test the config by running your config against a second, similar auto insurance document
- Use the API or SDKs to integrate your Sensible config with your application
- Validate extractions in production by using JsonLogic to define expected extracted values and flag unexpected values as warnings or errors
Get an account
-
Get an account at sensible.so. If you don't have an account, you can still read along to get a rough idea of how things work.
-
Log into the Sensible app.
Configure the extraction
-
In the Document Types tab, Click New document type to create a new document type. In the dialog:
- Download the following example document, then select it in the dialog for upload:
Example document Download link - For the document type name, enter
auto_insurance_quotes. - For the configuration name, enter
anyco, for the fictional name of an insurance company.
Note: For layout-based methods, you generally create one configuration for each company or vendor in a document type. - Deselect the Auto-generate configuration checkbox.
- Click Start extraction to create the document type.
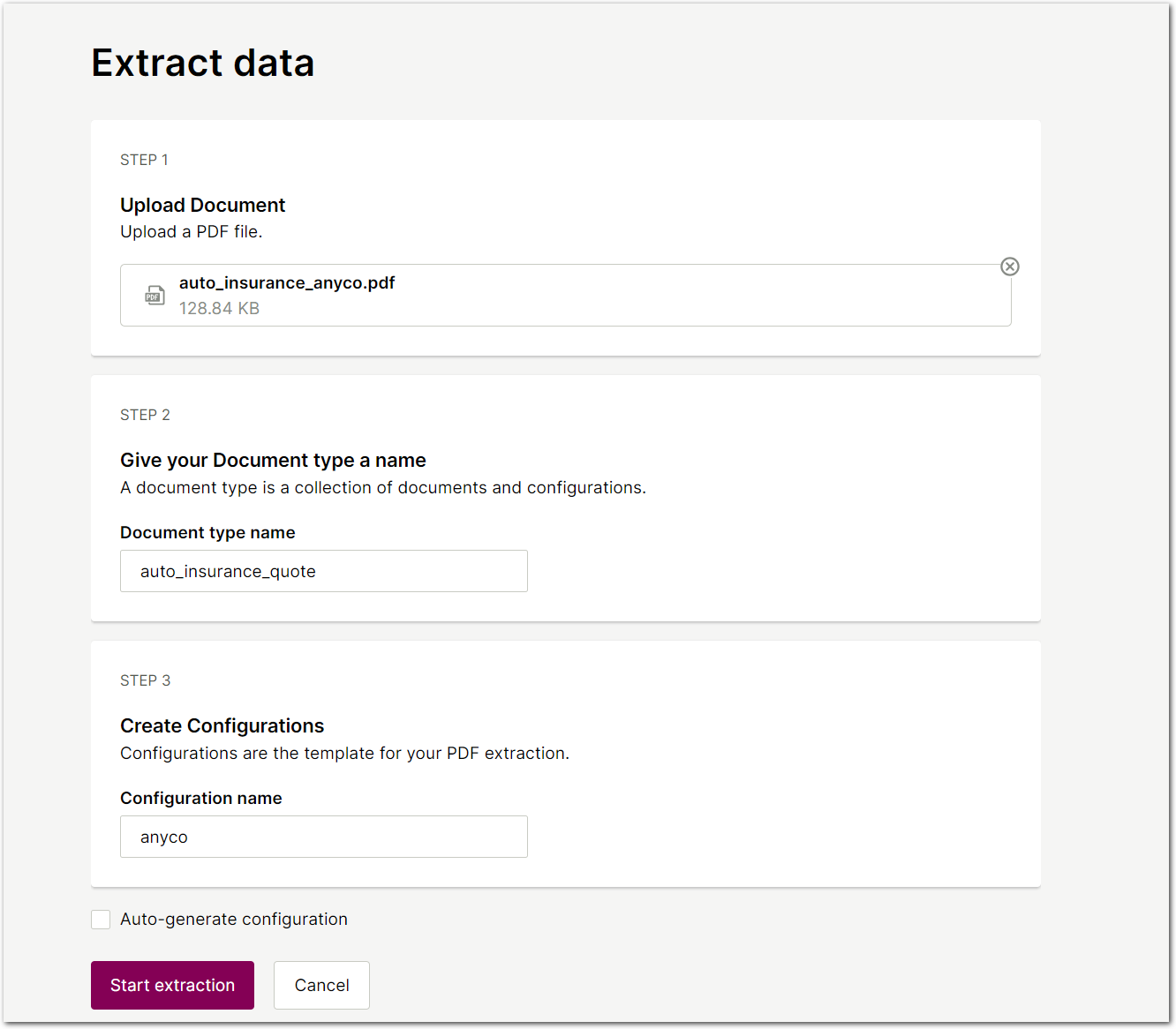
- Sensible displays the query editor for your config and example document. In this view, you see an empty config pane on the left, the document in the middle, and an empty output pane on the right:
Click the code bracket icon in the right pane to ensure you view the output as JSON.
Extract data
For this tutorial, you'll extract these fields:
- a couple of premiums
- the policy number
- the policy period
- Paste this config into the left pane in the editor to extract the data:
{
"fields": [
{
/* LLM-BASED METHOD */
"method": {
/* for this LLM-based method, no anchor is necessary */
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
{
/* describe target data for AI to extract */
"id": "bodily_injury_premium",
"description": "bodily injury premium",
"type": "currency"
},
{
"id": "customer_service_phone",
"description": "insurer's customer service phone number",
}
]
}
},
/* LAYOUT-BASED METHODS */
{
/* user-friendly ID for target data */
"id": "policy_period",
/* search for target data
near anchor text "policy period" in doc*/
"anchor": "policy period",
"method": {
/* target to extract is a single line
near anchor line ("policy period") */
"id": "label",
/* target data is to right of anchor line */
"position": "right"
}
},
{
/* user-friendly ID for target data */
"id": "comprehensive_premium",
/* target data is near text "comprehensive" */
"anchor": "comprehensive",
/* target data is a currency, else return null */
"type": "currency",
"method": {
/* target to extract is in a row */
"id": "row",
/* target is to right of anchor ("comprehensive") in row */
"position": "right",
/* grab 2nd row cell */
"tiebreaker": "second"
}
},
/* target data is text in a box
with anchor "policy number" */
{
"id": "policy_number",
"type": "string",
"anchor": {
"match": {
"text": "policy number",
"type": "startsWith"
}
},
"method": {
"id": "box"
}
}
]
}The following image shows this example in the Sensible app:
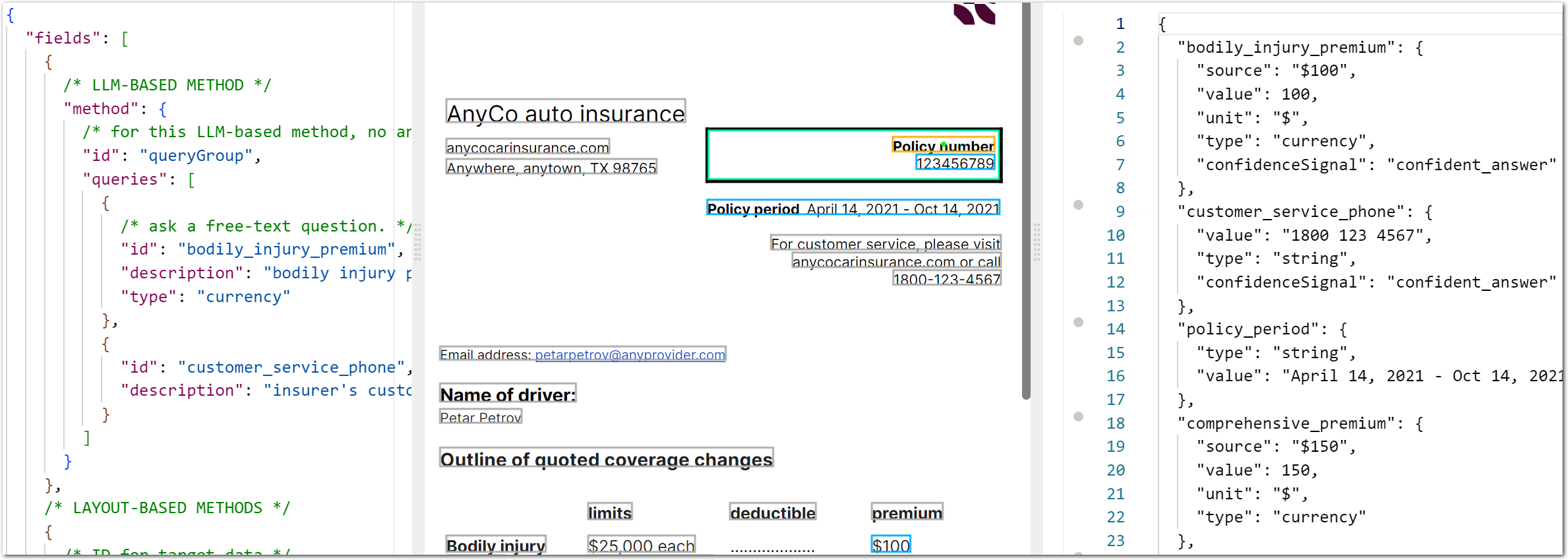
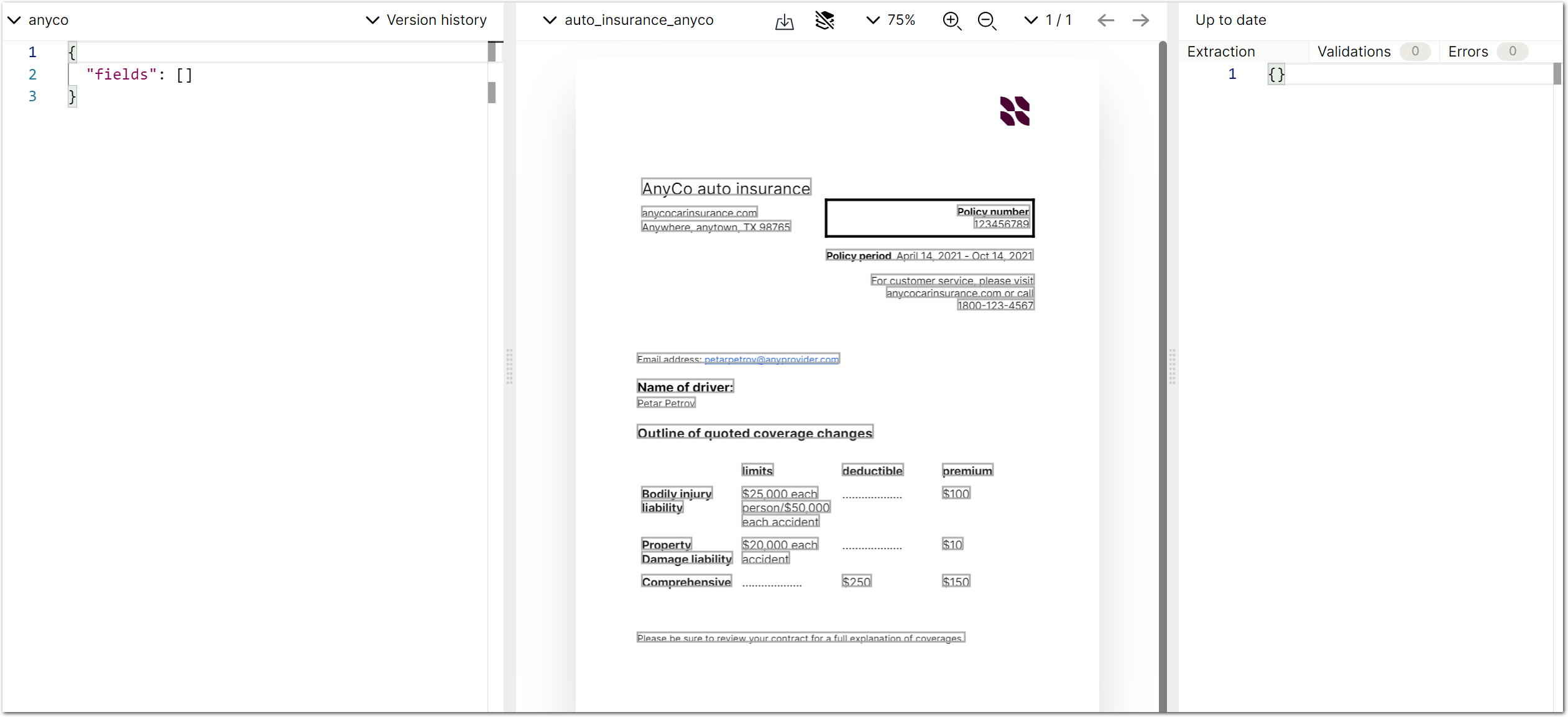
You should see the following extracted data in the right pane:
{
"bodily_injury_premium": {
"source": "$100",
"value": 100,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
},
"customer_service_phone": {
"value": "1800 123 4567",
"type": "string",
"confidenceSignal": "confident_answer"
},
"policy_period": {
"type": "string",
"value": "April 14, 2021 - Oct 14, 2021"
},
"comprehensive_premium": {
"source": "$150",
"value": 150,
"unit": "$",
"type": "currency"
},
"policy_number": {
"type": "string",
"value": "123456789"
}
}Congratulations! You created your first config and extracted your first document data. If you want to process car insurance quotes generated by a different company, you can create a new config and upload a new reference document.
-
For a deep dive on how the config works, see the following section.
-
If you want to skip ahead and try out the API or SDKs, see Integrate with your application.
How layout-based extraction works
This guide focuses on layout-based document extraction, which works as follows:
-
Each "field" is a basic query unit in Sensible. Each field outputs a piece of data from the document that you want to extract. Sensible uses the field
idas the key in the key/value JSON output. For more information, see Field. -
Sensible searches first for a text "anchor" because it's a computationally quick way to narrow down the location of the target data to extract. An anchor is text that always occurs close to your target text. Without it, Sensible wouldn't know which page to search in for your target text. For more information about defining complex anchors, see Anchor.
-
Then, Sensible uses a "method" to expand its search out from the anchor and extract the data you want. For more information about methods, see Layout-based methods.
This config uses three types of layout-based methods:
| Type of method | explanation | description |
|---|---|---|
| layout | How it works: label method | Grab info immediately proximate to labeling text. |
| layout | How it works: row method | Grab info from a cell in a row. |
| layout | How it works: box method | Grab info from a box. |
This config also uses one large language model (LLM)-based method, to demonstrate that you can combine layout-based and LLM-based methods in the same config:
| Type of method | explanation | description |
|---|---|---|
| LLM-based | How it works: query group method | Ask a free-text question about simple information in the document |
How it works: Query Group method
The easiest way to start extracting simple information is to author a natural-language question, or prompt, for a large language model (LLM).
For example, to extract the bodily injury liability:

The config uses the Query Group method to query for the bodily injury premium. You can group together other queries if the answers are located within a page or two of each other in the document. For example, in the group, the config also queries for the insurer's customer service phone number.
{
"method": {
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
{
"id": "bodily_injury_premium",
"description": "in the table, what's the bodily injury premium?",
"type": "currency"
},
{
"id": "customer_service_phone",
"description": "insurer's customer service phone number",
}
]
}
},This config returns:
{
"bodily_injury_premium": {
"source": "$100",
"value": 100,
"unit": "$",
"type": "currency",
"confidenceSignal": "confident_answer"
},
"customer_service_phone": {
"value": "1800 123 4567",
"type": "string",
"confidenceSignal": "confident_answer"
},Try it out: change one of the questions to "street address for the Anyco insurance company" and see what you get.
LLM-based methods such as the Query Group method can run up against limitations with complex document formatting. In such advanced cases, use layout-based methods to extract the target information.
Let's look next at several basic layout-based methods.
How it works: Label method
To extract the policy period from the document:

The config uses the Label method:
{
"id": "policy_period",
"anchor": "policy period:",
"method": {
"id": "label",
"position": "right"
}
}This describes the layout of the data to extract relative to the anchor:
- The anchor (
"policy period") is text that's pretty close to the text to extract, so it can serve as a "label" for that text ("id": "label"). - The text to extract is to the right of the anchor (
"position": "right").
This config returns:
"policy_period": {
"type": "string",
"value": " April 14, 2021 - Oct 14, 2021"
} You can extract text to the right, left, above, or below a label. For example, how would you use a label to extract the driver's name? Try it out.
Key concept: lines
See those gray boxes around the text in the following image?

Each gray box shows the boundaries for a "line." Sensible recognizes lines using whitespaces and other factors, so "lines" can occupy the same height on the page.
The Label method can operate in a single line, or on consecutive lines. Here's a question: for the preceding image, can you use the Label method to anchor on "Bodily injury" and return "$25,000 each"? Try it out:
{
"id": "doesnt_work_returns_null",
"anchor": "bodily injury",
"method": {
"id": "label",
"position": "right"
}
}This returns null, because the Label method works for text in the same line or in proximate lines. In this case, the problem is that the gap between the two lines of text is more than 0.2 inches:

Take a look instead at a purpose-built Row method instead to extract text in a table.
How it works: Row method
To extract the comprehensive premium of $150:

The config uses the Row method:
{
"id": "comprehensive_premium",
"anchor": "comprehensive",
"type": "currency",
"method": {
"id": "row",
"tiebreaker": "second",
}
}This describes the data to extract:
- The anchor text (
"comprehensive") is part of a row of lines ("id": "row"). - The returned value is a currency (
"type": "currency"). For other data types you can define, see Field query object. - The text to extract is the second line in the row after the anchor (
"tiebreaker": "second"). Use tiebreakers to select lines in rows, for example maximum and minimum values (<and>). - By default, the Row method extracts values to the right of the anchor. You can override the default by specifying (
"position":"left").
This returns:
"comprehensive_premium": {
"source": "$150",
"value": 150,
"unit": "$",
"type": "currency"
}But wait! Why didn't "tiebreaker": "second" select $250 instead of $150, since $250 is the second line after the anchor (the first line is ............)?
The reason is that "tiebreaker": "second" evaluates after the data type specified in the field, "type": "currency". Instead of looking for the second line after the anchor in general, Sensible looks for the second line that contains a currency. Convenient, right?
Key concept: visualize anchors and matches
In the app, you can visually inspect anchors and methods by looking at their color coding:
- Orange boxes show lines matched by the Anchor object.
- Blue boxes show lines matched by the Method object.
- Dotted blue boxes show lines discarded by the Method object. Seeing the entire method match in the app can help you troubleshoot unexpected output.
To continue the Row method example from the previous section, in the following image the orange box shows that "Comprehensive" is the anchor line:

The dotted blue boxes show you that the Row method matches all the lines in the row after the anchor, but then narrows down the actual output to $150 using "tiebreaker": "second".
How it works: Box method
To extract the policy number from this document:

The config uses the Box method:
{
"id": "policy_number",
"type": "string",
"anchor": {
"match":
{
"text": "policy number",
"type": "startsWith"
}
},
"method": {
"id": "box"
}
}This describes the data to extract:
- The anchor is inside a box (
"id": "box"). - The anchor text is
policy number. - The anchor line is a little more complex than previous examples, because it also defines a match type (
"type": "startsWith"). You can write a simpler string anchor as"anchor":"policy number", or you can expand to complex anchors. For more information, see Anchor object.
This returns:
"policy_number": {
"value": "123456789",
"type": "string"
}Note: Sensible extracts the box contents, but not the anchor itself. By default, Sensible returns method results, not anchor results.
Advanced layout-based queries
You can get more advanced with this auto insurance config. For example:
- The limits listed in the table are tricky for the Row method to capture since they can be a variable number of lines. Row methods depend on strict horizontal alignment of lines, so Sensible extracts the first line. Instead, use the NLP Table method to more reliably capture the data in each cell of the whole table.
- What if the document listed emails, and you wanted to capture all those emails? You could use a regular expression (regex) in a
"match":"all"anchor coupled with a Passthrough method, or the Regex method. - You can split the policy period into two dates, either by using the Split computed field method, or by setting the Date type on the field and using a tiebreaker.
To check out other methods, see Layout-based methods.
Test the config
Before integrating the config with an application and writing validation tests against it, double check the config by uploading another quote.
-
Repeat the steps in the previous section to upload a second generic car insurance quote:
auto_insurance_anyco_2 Download link -
Click the anyco config, select the "auto_insurance_anyco_2" document, and look at the output. Unlike the first document, the policy period takes up two lines, so Sensible misses the end year (2021):
{ "policy_period": { "type": "string", "value": "May 20, 2021 - Nov 20," }

That seems like sloppy document formatting, but let's work with it. There are several options for capturing the policy period reliably, including:
- Document Range method
- Region method
Alternative 1: Document Range method
You can use the Document Range method to extract the policy period. This method extracts succeeding lines of text after an anchor. You need to configure some optional parameters, because the Document Range method by default discards anchor lines. Since the date range is part of the anchor line (the line containing "policy period"), you need to specify to:
- include the anchor with
"includeAnchor": true - filter out unwanted text in the anchor (the words "Policy period") with a Word Filters parameter.
Try it out by replacing your existing policy_period field with this example:
{
"id": "policy_period",
"anchor": "policy period",
"method": {
"id": "documentRange",
"includeAnchor": true,
"wordFilters": [
"policy period"
],
"stop": {
"text": "for customer",
"type": "startsWith"
},
}
}Alternative 2: Region method
You can use the Region method to extract the policy period. A region is a rectangular space defined by coordinates relative to the anchor.
Replace the existing policy_period field with the following field in the Sensible app:
{
"id": "policy_period",
"anchor": {
"match": [
{
"text": "policy period",
"type": "startsWith"
}
]
},
"method": {
"id": "region",
"offsetX": -0.2,
"offsetY": -0.1,
"width": 3.6,
"height": 0.45,
"start": "left",
"wordFilters": [
"policy period",
]
}
},This field defines a region in inches relative to the anchor. Since the region overlaps the anchor, specify a Word Filters parameter to remove the anchor text in the output. See the green box representing the region in the editor? This box dynamically resizes as you adjust the region parameters (such as the Height and Start parameters), so you can visually tweak the region till you're satisfied.

Let's double check that this region also works with the first document:

Yes, it works too.
- Click Publish configuration and choose Production to save your changes to the config.
In a production scenario, continue testing documents until you have confidence your configs work with the document type you've defined. Then, write tests to validate the extractions in production.
Integrate with your application
When you're ready to integrate with your application, enable using the config with the Sensible SDKs or API by taking the following steps:
- Click Publish configuration. The config is still a work in progress, so click Development. Now you can use the query parameter
env=developmentto test the integration before you go to production: .
. - Use the Sensible SDKs or API to integrate with your application.
Validate extractions in production
In a previous section, you tested a couple of documents manually. Now it's time to scale up and quality control the extractions by writing tests that run for all API extractions in a doc type.
Use JsonLogic to validate that the extracted information makes sense for the car insurance document:
- Test that the property damage liability premium is cheaper than the comprehensive premium:
{"<":[{"var":"property_liability_premium.value"},{"var":"comprehensive_premium.value"}]}
- Test that the policy number is a nine-digit number:
{"match":[{"var":"policy_number.value"},"\\d{9}"]}
To add these tests:
- In the auto_insurance_quote document type, click Create validation. Add the following input to the dialog:
- Set the Severity to Warning
- Set the Description to "prop. damage is less than comprehensive"
- Set the Condition to:
{"<":
[
{"var":"property_liability_premium.value"},
{"var":"comprehensive_premium.value"}
]
}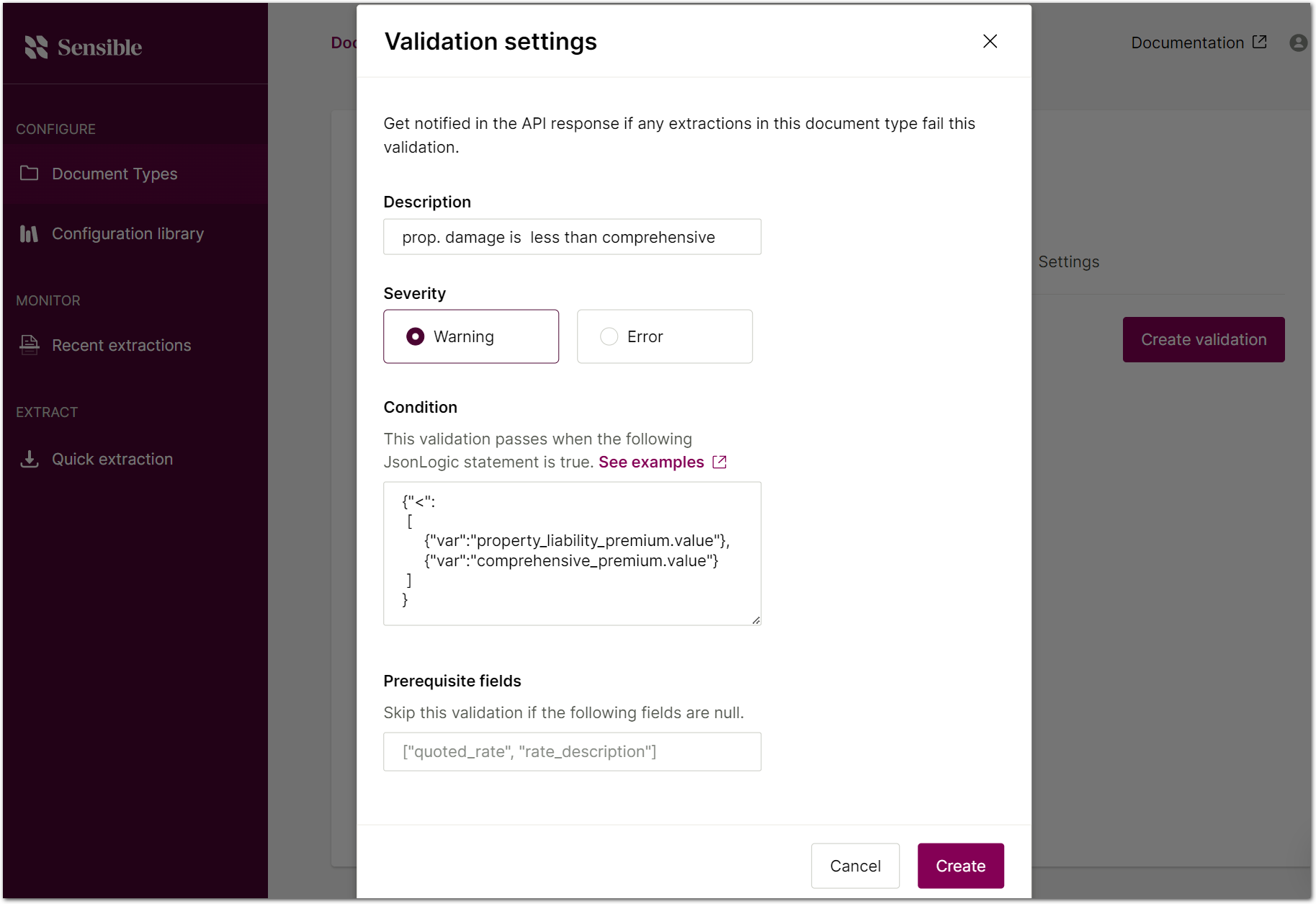
- Click Create.
- Repeat the previous steps to create another validation with the following settings:
- Set the Severity to Error
- Set the Description to "policy number is a nine-digit number"
- Set the Condition to:
{"match":
[
{"var":"policy_number.value"},"\\d{9}"
]
}-
To test the validations with a document that's missing information, try out an API call with the following example document. The document contains these errors:
- the policy number is missing
- the property damage liability premium is $200 more than the comprehensive premium
| auto_insurance_anyco_3 | Download link |
|---|
You should receive a response with errors and warnings in the Validations array, as shown in the following API response excerpt:
{
"id": "11404335-1ea4-4414-a5ca-1ccef568ebec",
"created": "2021-09-21T17:36:56.339Z",
"status": "COMPLETE",
"type": "auto_insurance_quote",
"configuration": "anyco",
"parsed_document": {
"policy_period": null,
"comprehensive_premium": {
"source": "$100",
"value": 100,
"unit": "$",
"type": "currency"
},
"property_liability_premium": {
"source": "$300",
"value": 300,
"unit": "$",
"type": "currency"
},
"policy_number": null
},
"validations": [
{
"description": "prop. damage less than comprehensive",
"severity": "warning"
},
{
"description": "policy number is a nine-digit number",
"severity": "error"
}
],
"validation_summary": {
"fields": 4,
"fields_present": 2,
"errors": 1,
"warnings": 1,
"skipped": 0
}
}Use validation errors and warnings to automatically flag poor-quality extractions for human review in the Sensible app.
Next
- Check out the SenseML reference docs to write your own extractions
- Learn about integration options.
Updated 6 months ago