

Row
Matches all lines to the left or right of the anchor line.
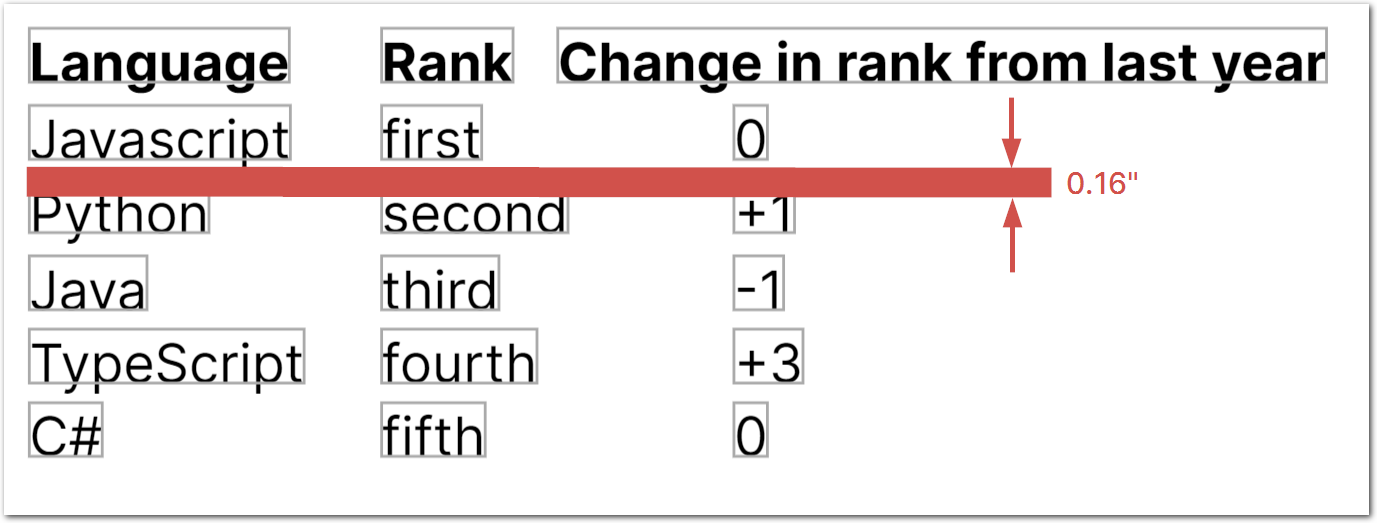
A "row" is lines of text distributed along a horizontal line. By default, each matching line in the "row" must have a top boundary that's within 0.08 inches below or above the anchor's top boundary (total range is 0.16" inches). For example, the following image shows a red line that defines the alignment for the row of text that begins with "Python":
Parameters
| key | value | description |
|---|---|---|
| id (required) | row | |
| includeAnchor | boolean. default: false | Includes the anchor line in the method output |
| position | right, left. default: right | Matches to the left or right |
| tiebreaker | For information about this global parameter, see Method. | For information about this global parameter, see Method. |
| tolerance | number in inches. default: 0.08 | Configure this for unusual font sizes. By default, each matching line in the "row" must have a top boundary that's within 0.08 inches below or above the anchor's top boundary (total range is 0.16" inches). The default tolerance of 0.08 works well for font sizes around 12 pts (~0.17 inches). Configure this default when the font size of the row is unusual. For example, if your font size is a tiny 1.44 pt (0.02 inches), set this parameter to 0.01. |
Syntax example
The following example shows the preceding parameters documented with in-line comments.
/* Sensible uses JSON5 to support in-line comments*/
{
"id": "field1", /* user-friendly ID for extracted target data */
"anchor": "some text" /* an anchor is text that always occurs in the same position relative to your target data. Without an anchor, Sensible wouldn't know which page to search in for your target data. */,
"method": {
"id": "row", /* target data to extract is distributed on same horizontal line as anchor */
"position": "right", /* default: right. target data is to left or right of data. enums: left | right. */
"tiebreaker": "second" /* extract the line in the second non-empty cell to the left of the anchor. default: returns all cells. for more information about this global method, see Method topic */
"tolerance": 0.1 /* default: 0.08. number in inches. Configure for unusual font sizes. By default, each matching line in the "row" must have a top boundary that's within 0.08 inches below or above the anchor's top boundary (total range is 0.16" inches). */
}
}
Examples
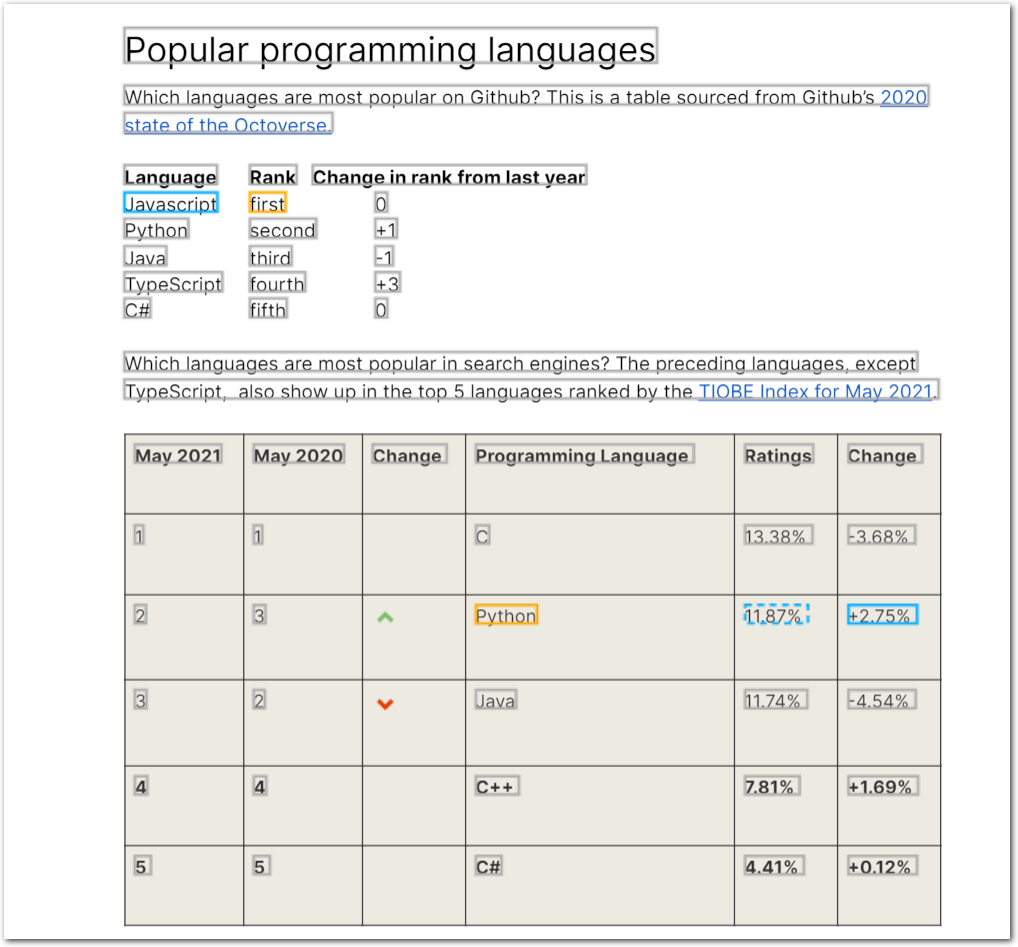
The following example shows extracting data from two consecutive tables using the Row method:
- The first field has an anchor with two matches to avoid duplicate text in the second table. First the anchor matches the text
most popular on github, then it anchors on the textfirstin a row. The method then extracts the top-ranked GitHub language name to the left of the anchor match. - The second field also has an anchor with two matches. It anchors on the row containing
Python, then extracts the second percentage in the row to the right of the anchor.
Config
{
"fields": [
{
"id": "number_1_language_on_github", /* user-friendly ID for extracted target data */
"anchor": { /* an anchor is text that always occurs in the same position relative to your target data. */
"match": [ /* array of Match objects. Sensible matches the last element
if each element matches a successive line in the document */
{
"text": "most popular on github", /* string to match */
"type": "includes" /* match anywhere in line. */
},
{
"text": "first", /* string to match */
"type": "startsWith" /* line must start with the match */
}
]
},
"method": {
"id": "row", /* target data to extract is distributed on same horizontal line as anchor */
"position": "left", /* target data is to left of anchor. */
}
},
{
"id": "python_change_in_TIBOE_rating", /* user-friendly ID for extracted target data */
"type": "percentage", /* Sensible formats extracted data as this data type, or returns null if it doesn't recognize extracted data as the specified type */
"anchor": { /* an anchor is text that always occurs in the same position relative */
"match": [ /* array of Match objects. Sensible matches the last element if each element matches a successive line in the document */
{
"text": "popular in search engines", /* string to match */
"type": "includes" /* match anywhere in line. */
},
{
"text": "Python", /* string to match */
"type": "startsWith" /* line must start with the match */
}
]
},
"method": {
"id": "row", /* target data to extract is distributed on same horizontal line as anchor */
"tiebreaker": 1 /* extract the line in the first non-empty cell to the right of the anchor. */
}
}
]
}Example document
The following image shows the data extracted by this config for the following example document:
| Example document | Download link |
|---|
Output
{
"number_1_language_on_github": {
"value": "Javascript",
"type": "string"
},
"python_change_in_TIBOE_rating": {
"source": "2.75%",
"value": 2.75,
"type": "percentage"
}
}Notes
- To extract an entire table, see the table methods.
- To extract a column, see the Column method.
- In a row with optional empty cells, a tiebreaker can return lines from inconsistent columns. Use the Intersection method instead.
- The Row method can't extract multiple lines in a cell. Use the Document Range or Intersection methods instead.
Updated about 1 month ago
Did this page help you?