

SenseML reference introduction
Use the SenseML query language to extract structured data from documents, for example, auto insurance quotes, home inspection reports, or your custom documents. For a brief overview of SenseML, see Overview.
See the following topics for reference documentation for the SenseML query language:
- Field query object
- Preprocessors
- LLM-based methods and layout-based methods. For more information about choosing whether to author layout- or LLM-based methods, see Choosing an extraction approach.
- Configuration settings
- Computed Field methods
- Sections
- Conditional execution of SenseML
- Large spreadsheet extraction
- Postprocessor
You can use all of the preceding SenseML features to write a config to handle a collection of similar documents. A config specifies how to extract data and how to populate a target output schema. Publish the config so that you can automate extracting document data using one of Sensible integration options.
Examples
For an overview, see the following example of a short config:
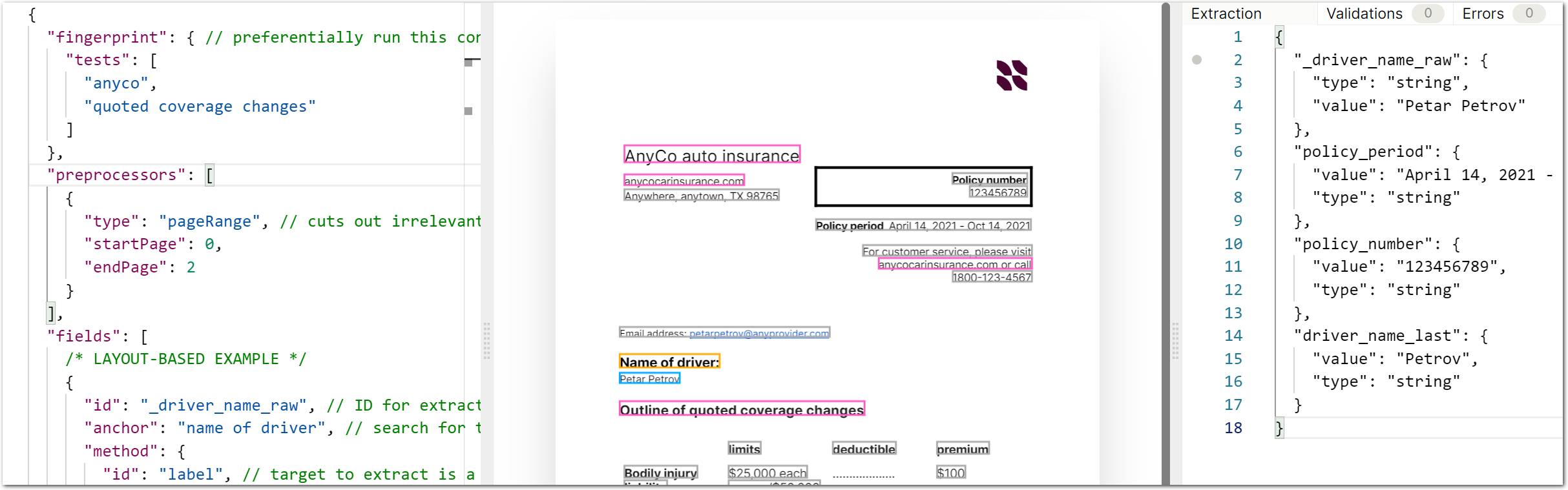
Try out this example in the Sensible app using the following document and config:
| Example document | Download link |
|---|
This example uses the following config:
{
"fingerprint": { // preferentially run this config if doc contains the test strings
"tests": [
"anyco",
"quoted coverage changes"
]
},
"preprocessors": [
{
"type": "pageRange", // cuts out irrelevant doc pages before extraction
"startPage": 0,
"endPage": 2
}
],
"fields": [
/* LAYOUT-BASED EXAMPLE */
{
"id": "_driver_name_raw", // ID for extracted target data
/* an anchor is text that always occurs in the same position relative
to your target text.
Without an anchor, Sensible wouldn't know
which page to search in for your target text.
*/
"anchor": "name of driver",
/* The method specifies how to spatially expand out from
the anchor text ("name of driver") to find the target text.
*/
"method": {
"id": "label", // target to extract is a single line near anchor line
"position": "below" // target is below anchor line ("name of driver")
}
},
/* LLM-BASED EXAMPLE */
{
/* no need for an anchor. Sensible searches the whole document
for the answers to the LLM prompts
*/
"method": {
/* to improve performance, group queries if their answers
are co-located in the document
*/
"id": "queryGroup",
"searchBySummarization": "page",
"queries": [
{
"id": "policy_period",
/* prompt an LLM to extract the data you describe.
use simple, short language
*/
"description": "policy period",
"type": "string"
},
{
"id": "policy_number",
"description": "policy number",
"type": "string"
}
]
}
},
],
"computed_fields": [
{ // target data is a transformation of already extracted data
"id": "driver_name_last", // ID for transformed target data
"method": {
"source_id": "_driver_name_raw", // extracted data to transform
"id": "split", // target data is substring in extracted data
"separator": " ", // use a whitespace space to split the extracted data into substring array
"index": 1 // target is 2nd element in substring array
}
}
]
}The output of this example config is as follows:
{
"_driver_name_raw": {
"type": "string",
"value": "Petar Petrov"
},
"policy_period": {
"value": "April 14, 2021 - Oct 14, 2021",
"type": "string"
},
"policy_number": {
"value": "123456789",
"type": "string"
},
"driver_name_last": {
"value": "Petrov",
"type": "string"
}
}This example config has the following elements:
-
Fields are queries that extract text. For more information, see Field query object.
-
The preprocessor,
pageRange, cuts out irrelevant pages of the document. For more information about using preprocessors to clean up documents before extracting data, see Preprocessors. -
The fingerprint tells Sensible to preferentially run this config if the document contains the terms "anyco" or "quoted coverage changes." For more information about using fingerprints to improve performance, and other configuration settings, see Configuration Settings.
-
The computed field
"driver_name_last"extracts the last name from the raw output of the_driver_name_rawfield. For more information about transforming field output, see Computed field methods. You can also capture the full name as typed output. See types.
Using SenseML, you can extract just about any data from a document. Happy extracting!
Updated 7 months ago