

List
This LLM-based method extracts repeating data in a document based on your description of the list’s overall contents and items. This method is suited to extracting data such as the work history on a resume, the vehicles on an auto insurance policy, or the line items on an invoice.
Use this method when your target data can appear either as a table or as another layout. For example, the List method can find:
- data in paragraphs of free text or in more structured layouts, such as key/value pairs or tables.
- data in other extracted fields, when you configure the Source Fields parameter. In other words, you can extract data with one prompt, then apply further prompts to the extracted data.
This method is an alternative to the NLP Table method.
Limitations
- Sensible can output lists of different maximum lengths depending on how you configure the LLM Engine and Single LLM Completion parameters. If the extracted list exceeds the limit, Sensible truncates the list.
- For highly complex repeating layouts, such as insurance loss run documents, use the Sections method.
Prompt tips
- The list description describes the overall contents for the list, while each property is a single description of an item that repeats in the list.
- For more information about how to write descriptions, or "prompts", see Query Group extraction tips.
- For advanced options, see Advanced LLM prompt configuration.
For information about how this method works, see Notes.
Parameters
Note You can configure some of the following parameters in both the NLP preprocessor and in a field's method. If you configure both, the field's parameter overrides the NLP preprocessor's parameter.
| key | value | description | interactions |
|---|---|---|---|
| id (required) | list | ||
| description (required) | string | A prompt describing the list's subject matter as a whole. | |
| properties (required) | object | An array of objects with the following parameters: - id (required): A user-friendly ID for the data in the extraction output. - description (required): A prompt describing the list item that you want to extract. You can prompt the LLM to reformat or filter the data. For example, provide prompts like " transaction amount. return the absolute value" or "vehicle make (not model)". - type: The list item's type. For more information, see types. | |
| CONTEXT COMPLETNESS AND TROUBLESHOOT PROMPT | |||
| llmEngine | object | Configures the LLM model Sensible uses to extract data from the context. Contains the following parameters:provider: Contains the following options:- open-ai (default): Sensible uses an OpenAI model. - anthropic: Sensible uses an Anthropic model.- google: Sensible uses a Google model.For more information about models, see LLM models. Select this option to troubleshoot situations in which Sensible correctly identifies the part of the document that contains the answers to your prompts, but the LLM's answer contains problems. For example, Sensible returns an LLM error because the answer isn't properly formatted, or the LLM doesn't follow instructions in your prompt. mode: Contains the following options- fast (default): Sensible uses a faster LLM model. - thorough: Sensible uses a slower and more powerful LLM model. Sensible can take several minutes to return the list. Use this option if the Fast parameter results in incomplete extractions for multi-page lists.- long: Sensible uses a faster LLM model. If you set this value, then Sensible can output lists extracted from up to 100 one-page source chunks. Otherwise Sensible by default extracts from 20 one-page chunks. If the list in the document is longer than the number of source chunks, Sensible truncates the list.For more information, see Notes. | If you set the Mode parameter to Long, then Sensible sets the Chunk Count parameter to 100. |
| singleLLMCompletion | boolean. default: false | If Sensible returns incomplete or duplicate results in a list that's under ~20 pages long, set this parameter to True to troubleshoot. If true, Sensible concatenates the top-scoring chunks into a single batch to send as context to the LLM, instead of batching calls to the LLM. By avoiding splitting context, you can avoid problems such as the LLM failing to recognize the end of one list and the start of another. For more information, See Notes. - The following limits apply: - If the extracted list exceeds the output limit for a single API response from an LLM engine (~16k tokens or ~20 pages for all supported LLM engines), Sensible truncates the list. - Rarely, Sensible fails to truncate a list at ~16k token output and returns an error. This can happen if the source text in the context has a very small font size. To avoid this type of error, set this parameter to false. | Don't set this parameter to true if you set the LLM Engine parameter to Long. The Single LLM Completion parameter limits output to ~16k tokens, so it'll truncate longer lists. |
| CHAIN PROMPTS | |||
| source_ids | array of field IDs in the current config | If specified, prompts an LLM to extract data from another field's output. For example, if you extract a field _checking_transactions and specify it in this parameter, then Sensible answers the prompts rank deposits by size and reformat withdrawals with a minus sign if they're formatted with parentheses using _checking_transactions rather than searching the whole document to locate the context. Note that the _checking_transactions field must precede the transactions_frequencies field in the fields array in this example. For more information about this example, see Example: Extract data from other fields.You can use a JavaScript-flavored regular expression to specify all field IDs that contain a pattern. For example, to specify all the field IDs containing the text wage extracted from a W-2 form, you can write "source_ids": { "pattern": ".*wage.*" }. For more information and an example, see Example: Chain prompts with regex.The source field IDs can reference document data extracted from the current extraction, or caller-provided data such as data from a previous extraction or from a system of record. To supply caller-provided values, use the Extra Data method to create a field from a value in the request's extra_data object, then include that field ID in source_ids. | If you configure this parameter, then generally don't configure: - LLM Engine parameter - Single LLM Completion parameter - If you configure this parameter, Sensible doesn't support the following parameters: - Anchor parameter in the field - Multimodal Engine parameter - Search By Summarization parameter - Chunk Count parameter - Page Range parameter |
| FIND CONTEXT | |||
| searchBySummarization | boolean, or outline, or page (equivalent to true)default: false | (Recommended) Configure this to search for context using summaries of document chunks. If you set page, each page is a chunk. If you set outline, an LLM outlines the document, and each segment of the outline is a chunk.For more information, see Advanced LLM prompt configuration. This parameter is compatible with documents up to 1,280 pages long. For an example, see the Multicolumn preprocessor. | If you configure this parameter for a document 5 pages or under in length, Sensible submits the entire document as context, bypassing summarization. If you configure this parameter for a document over 5 pages long, then Sensible sets the Chunk Count parameter to 5 and ignores any configured value. |
| pageRange | object | Configures the possible page range for finding the context in the document. If specified, Sensible creates chunks in the page range and ignores other pages. For example, use this parameter to improve performance, or to avoid extracting unwanted data if your prompt has multiple candidate answers. Contains the following parameters: startPage: Zero-based index of the page at which Sensible starts creating chunks (inclusive). endPage: Zero-based index of the page at which Sensible stops creating chunks (exclusive). | Sensible ignores this parameter when searching for a field's anchor. If you want to exclude the field's anchor using a page range, use the Page Range preprocessor instead. |
| CONFIGURE CONTEXT SIZE | |||
| chunkCount | number. default: 20 | The number of top-scoring document chunks Sensible combines as context as part of the full prompt it submits to an LLM. | See LLM Engine parameter for interactions. |
Examples
The following example shows using the List method to extract information from a menu about listed menu items.
Config
{
"fields": [
{
/* the id is a user-friendly name for the target list */
"id": "dinners",
"type": "table",
"method": {
"id": "list",
"searchBySummarization": "page",
/* overall description of list's contents */
"description": "dinner special menu items",
"properties": [
{
/* for each item in the list, provide a user-friendly ID and
description of the data you want to extract
and optional instructions to filter or reformat the data */
"id": "dinner_description",
"description": "entree description"
},
/* optional: target data is a currency */
{
"id": "price",
"type": "currency",
"description": "dinner price"
},
]
}
},
{
"id": "desserts",
"type": "table",
"method": {
"id": "list",
"searchBySummarization": "page",
"description": "dessert special menu items",
"properties": [
{
"id": "dessert_description",
"description": "dessert description"
},
{
"id": "price",
"type":"currency",
"description": "dessert price"
},
]
}
},
{
"id": "wines",
"type": "table",
"method": {
"id": "list",
"searchBySummarization": "page",
/* optional: try restricting the list to white wines,
or try making a new list for liquors and their serving sizes */
"description": "red wines and white wines (not other drinks such as beers or liquors)",
"properties": [
{
"id": "wine_name",
"description": "wine brand name"
},
{
"id": "wine_type",
"description": "wine varietal name (not brand), for example, return 'Red:cabernet savignon' or 'white:varietal not found'"
},
{
"id": "wine_description",
"description": "wine description"
},
{
"id": "smallest_serving_price",
"description": "smallest wine serving size and its dollar price, formatted like '6 oz: $11'"
},
{
"id": "second_smallest_serving_price",
"description": "second-smallest wine serving size and its dollar price, formatted like '6 oz: $11'"
},
{
"id": "bottle_price",
"type":"currency",
"description": "price per bottle, in dollars"
},
]
}
},
],
"computed_fields": [
/* optional: for cleaner output, zip each list */
{
"id": "dinners_zipped",
"method": {
"id": "zip",
"source_ids": [
"dinners",
]
}
},
{
"id": "desserts_zipped",
"method": {
"id": "zip",
"source_ids": [
"desserts",
]
}
},
{
"id": "wines_zipped",
"method": {
"id": "zip",
"source_ids": [
"wines",
]
}
},
/* optional: for cleaner output, remove the source
fields. */
{
"id": "hide_fields",
"method": {
"id": "suppressOutput",
"source_ids": [
"dinners",
"desserts",
"wines"
]
}
}
]
}Example document
The following image shows the example document used with this example config:
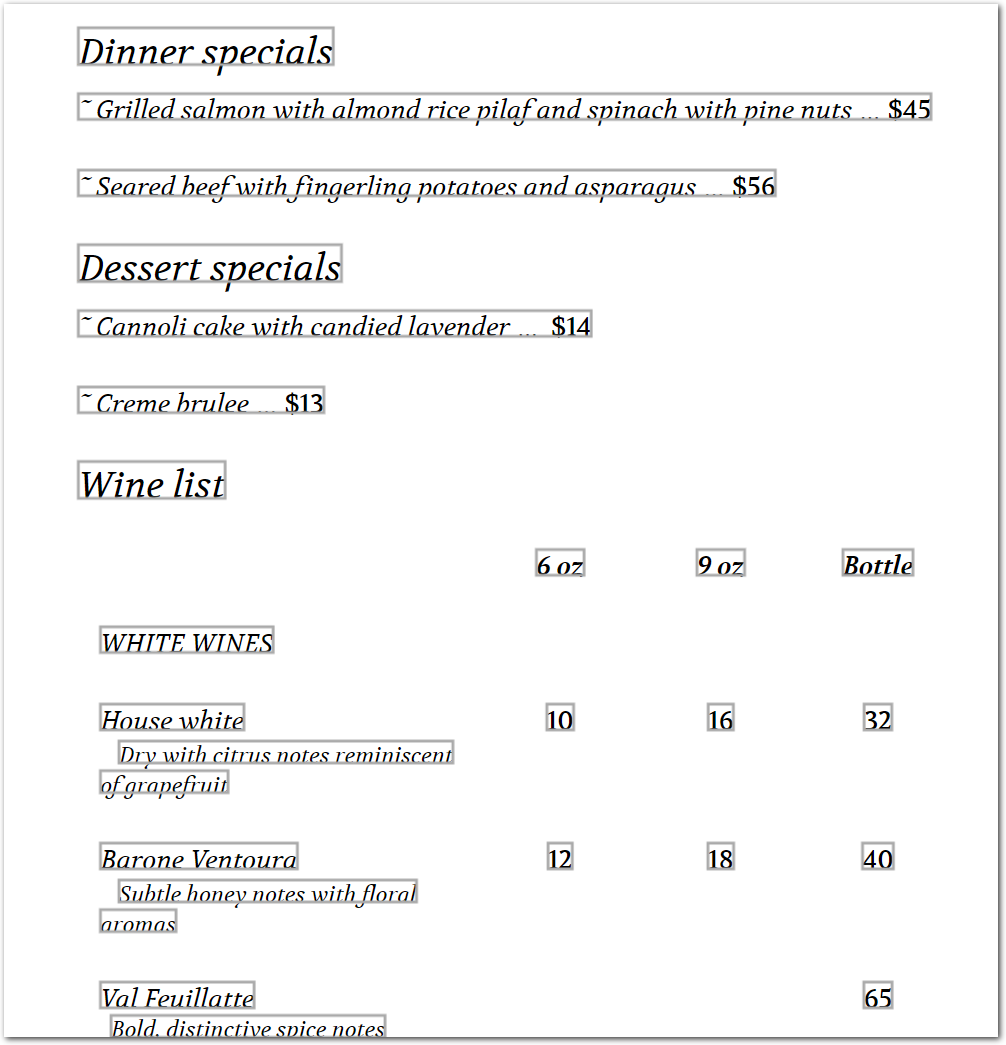
| Example document | Download link |
|---|
Output
{
"dinners_zipped": [
{
"dinner_description": {
"value": "Grilled salmon with almond rice pilaf and spinach with pine nuts",
"type": "string"
},
"price": {
"source": "$45",
"value": 45,
"unit": "$",
"type": "currency"
}
},
{
"dinner_description": {
"value": "Seared beef with fingerling potatoes and asparagus",
"type": "string"
},
"price": {
"source": "$56",
"value": 56,
"unit": "$",
"type": "currency"
}
}
],
"desserts_zipped": [
{
"dessert_description": {
"value": "Cannoli cake with candied lavender",
"type": "string"
},
"price": {
"source": "$14",
"value": 14,
"unit": "$",
"type": "currency"
}
},
{
"dessert_description": {
"value": "Creme brulee",
"type": "string"
},
"price": {
"source": "$13",
"value": 13,
"unit": "$",
"type": "currency"
}
}
],
"wines_zipped": [
{
"wine_name": {
"value": "House white",
"type": "string"
},
"wine_type": {
"value": "white:varietal not found",
"type": "string"
},
"wine_description": {
"value": "Dry with citrus notes reminiscent of grapefruit",
"type": "string"
},
"smallest_serving_price": {
"value": "6 oz: $10",
"type": "string"
},
"second_smallest_serving_price": {
"value": "9 oz: $16",
"type": "string"
},
"bottle_price": {
"source": "32",
"value": 32,
"unit": "$",
"type": "currency"
}
},
{
"wine_name": {
"value": "Barone Ventoura",
"type": "string"
},
"wine_type": {
"value": "white:varietal not found",
"type": "string"
},
"wine_description": {
"value": "Subtle honey notes with floral aromas",
"type": "string"
},
"smallest_serving_price": {
"value": "6 oz: $12",
"type": "string"
},
"second_smallest_serving_price": {
"value": "9 oz: $18",
"type": "string"
},
"bottle_price": {
"source": "40",
"value": 40,
"unit": "$",
"type": "currency"
}
},
{
"wine_name": {
"value": "Val Feuillatte",
"type": "string"
},
"wine_type": {
"value": "white:varietal not found",
"type": "string"
},
"wine_description": {
"value": "Bold, distinctive spice notes",
"type": "string"
},
"smallest_serving_price": null,
"second_smallest_serving_price": null,
"bottle_price": {
"source": "65",
"value": 65,
"unit": "$",
"type": "currency"
}
},
{
"wine_name": {
"value": "House red",
"type": "string"
},
"wine_type": {
"value": "red:varietal not found",
"type": "string"
},
"wine_description": {
"value": "A satisfying blend",
"type": "string"
},
"smallest_serving_price": {
"value": "6 oz: $11",
"type": "string"
},
"second_smallest_serving_price": {
"value": "9 oz: $17",
"type": "string"
},
"bottle_price": {
"source": "33",
"value": 33,
"unit": "$",
"type": "currency"
}
},
{
"wine_name": {
"value": "Wrath cabernet sauvignon",
"type": "string"
},
"wine_type": {
"value": "red:cabernet sauvignon",
"type": "string"
},
"wine_description": {
"value": "Bold with oak notes",
"type": "string"
},
"smallest_serving_price": null,
"second_smallest_serving_price": null,
"bottle_price": {
"source": "62",
"value": 62,
"unit": "$",
"type": "currency"
}
},
{
"wine_name": {
"value": "Turbell Estate Pinot noir",
"type": "string"
},
"wine_type": {
"value": "red:pinot noir",
"type": "string"
},
"wine_description": {
"value": "Mellow with dark chocolate notes",
"type": "string"
},
"smallest_serving_price": {
"value": "6 oz: $13",
"type": "string"
},
"second_smallest_serving_price": {
"value": "9 oz: $18",
"type": "string"
},
"bottle_price": {
"source": "35",
"value": 35,
"unit": "$",
"type": "currency"
}
},
{
"wine_name": {
"value": "Chappellet Shiraz",
"type": "string"
},
"wine_type": {
"value": "red:shiraz",
"type": "string"
},
"wine_description": {
"value": "Complex and subtle",
"type": "string"
},
"smallest_serving_price": null,
"second_smallest_serving_price": null,
"bottle_price": {
"source": "72",
"value": 72,
"unit": "$",
"type": "currency"
}
}
]
}
Example: Extract data from other fields
The following example shows how to prompt an LLM to get repeating data about another field's output.
Config
{
"fields": [
{
/* define section group containing businesses */
"id": "_businesses",
"type": "sections",
"range": {
"anchor": {
/* each business section starts with "Business #" */
"match": {
"type": "regex",
"pattern": "Business [0-9]"
}
}
},
/* return each business as object containing names, sales, and selected classification */
"fields": [
{
"id": "name",
"anchor": "name",
"method": {
"id": "passthrough",
}
},
{
"id": "sales",
"anchor": "sales",
"method": {
"id": "passthrough",
}
},
{ /* get checkbox status for 'individual' classification */
"id": "individual",
"type": "boolean",
"method": {
"id": "nearestCheckbox",
"position": "left"
},
"anchor": "individual"
},
{ /* get checkbox status for 'parternship' classification */
"id": "partnernship",
"type": "boolean",
"method": {
"id": "nearestCheckbox",
"position": "left"
},
"anchor": "partnership"
},
{ /* get checkbox status for 'llc' classification */
"id": "llc",
"type": "boolean",
"method": {
"id": "nearestCheckbox",
"position": "left"
},
"anchor": "limited"
},
{
/* return the selected classification for the business */
"id": "selected_classification",
"method": {
"id": "pickValues",
// select match:one for a group of radio buttons where the user can select a single item
"match": "one",
"source_ids": [
"individual",
"partnership",
"llc"
]
}
}
]
},
/* prompt an LLM to find answers in the `_business` section output */
{
"id": "_business_sales",
"type": "table",
"method": {
"id": "list",
/* use _businesses ID as context for prompts */
"source_ids": [
"_businesses"
],
"description": "business attributes",
"properties": [
{
"id": "name",
/* clean up source output, e.g., transform
"Name: ACME co" to "AMCE co" */
"description": "name of the business"
},
{
/* compare sales rankings */
"id": "sales_rank",
"description": "relative rank in annual sales compared to other businesses in this context, i.e., return 1st, 2nd, 3rd"
}
]
}
},
{
/* count instances of individual, parternship, and llc classified businesses */
"id": "_business_classifications_frequency",
"type": "table",
"method": {
"id": "list",
"source_ids": [
/* count instances in the _businesses output */
"_businesses"
],
"description": "business classifications",
"properties": [
{
"id": "business classification",
"description": "business classification, ie. llc or solo proprietor"
},
{
"id": "frequency",
"description": "how many times the business classification was selected"
}
]
}
},
/* zip output for more readable results */
{
"id": "business_sales",
"method": {
"id": "zip",
"source_ids": [
"_business_sales",
]
}
},
{
"id": "business_classifications_frequency",
"method": {
"id": "zip",
"source_ids": [
"_business_classifications_frequency",
]
}
},
/* hide source fields for more readable results */
{
"id": "clean_output",
"method": {
"id": "suppressOutput",
"source_ids": [
"_businesses",
"_business_classifications_frequency",
"_business_sales"
]
}
}
]
}Example document
The following image shows the example document used with this example config:

| Example document | Download link |
|---|
Output
{
"business_sales": [
{
"name": {
"value": "ACME co",
"type": "string"
},
"sales_rank": {
"value": "2nd",
"type": "string"
}
},
{
"name": {
"value": "Anyco LLM",
"type": "string"
},
"sales_rank": {
"value": "1st",
"type": "string"
}
},
{
"name": {
"value": "Keystone LLM",
"type": "string"
},
"sales_rank": {
"value": "3rd",
"type": "string"
}
}
],
"business_classifications_frequency": [
{
"business classification": {
"value": "individual",
"type": "string"
},
"frequency": {
"value": "1",
"type": "string"
}
},
{
"business classification": {
"value": "llc",
"type": "string"
},
"frequency": {
"value": "2",
"type": "string"
}
}
]
}Notes
For an overview of this method's default approach to locating context, see the following steps.
For alternate approaches, see Advanced LLM prompt configuration.
How it works by default
-
Sensible finds the chunks of the document that most likely contain your target data:
- Sensible splits the document into equal-sized chunks.
- Sensible scores each chunk by its similarity to the concatenated Description parameters.
- Sensible selects a number of the top-scoring chunks:
- If you specify Thorough or Long for the Mode parameter in the LLM Engine parameter, the Chunk Count parameter determines the number of top-scoring chunks Sensible selects to submit to the LLM.
- If you specify Fast for the Mode parameter, 1. Sensible selects a number of top-scoring chunks as determined by the Chunk Count parameter. 2. To improve performance, Sensible removes chunks that are significantly less relevant from the list of top-scoring chunks. The number of chunks Sensible submits to the LLM can therefore be smaller than the number specified by the Chunk Count parameter.
-
Sensible batches the selected chunks into groups. The chunks in each page group can come from non-consecutive pages in the document.
- If you set the Single LLM Completion parameter to True, then Sensible creates a single group that contains all the top-scoring chunks and sets a larger maximum token input limit for the single group (about 120k tokens) than it does for batched groups.
-
For each chunk group, Sensible submits a full prompt to an LLM. The full prompt includes the chunks as context, page-hinting data, and your prompts. The full prompt instructs the LLM to create a list formatted as a table, based on the context.
-
Sensible concatenates the results from the LLM for each page group and returns a list, formatted as a table.
Updated 3 months ago