

Extracting handwriting and OCR text
This topic contains tips and tricks for extracting handwriting and OCR'd text, for example from scanned documents or images:
OCR tips
Sensible provides confidence scores for OCR'd text in the extraction when you configure high verbosity, so you know whether the extracted output comes from high- or low-quality text images. For document types that use OCR, write validations to warn you about extractions from low-quality scans.
Handwriting tips
-
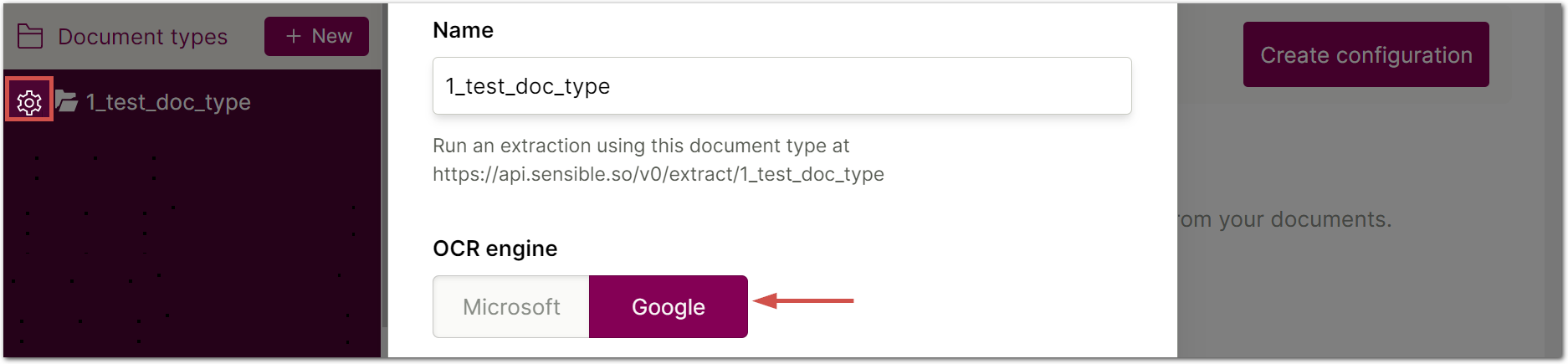
Choosing an OCR engine: Choose Google OCR. To configure OCR, click the gear icon for the Document Type and select Google:
-
Defining regions: Handwriting can occupy an unpredictable region or even overlap other lines. To capture handwriting, Sensible recommends defining a region with a small height and long width that runs through the middle of the area that can contain the handwriting. The green boxes in the following image show this approach:
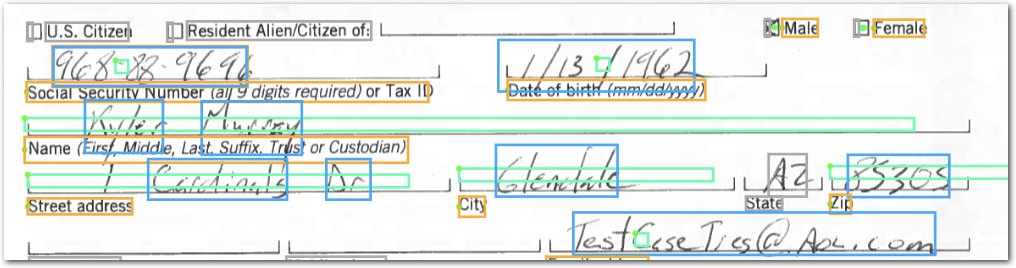
For more information about how Sensible determines whether to extract a line that partially overlaps a region, see Region.
-
Correcting for vertical misalignment: Jitter in the vertical positions of handwritten lines can cause Sensible to incorrectly sort lines that a human reader interprets as following left to right. The Sort Lines parameter corrects this problem by sorting lines by their likely reading order. For more information, see Sort Lines example.
Updated 7 months ago