

Try asynchronous extraction from your URL
Use Sensible's asynchronous endpoints in production scenarios. You have two options for asynchronous processing:
-
Provide your own URLs for your documents.
-
Use URLs provided by Sensible for your documents.
This topic covers providing your own URLs. This is a good option if you host your documents at either publicly accessible or a pre-signed URLs. The URL must respond to GET requests with document bytes.
For either option, you can get the results as soon as they're ready by specifying a webhook.
Extract from a URL you provide
Prerequisites
To follow these tutorials, you need:
- An API key. Create this key after you sign up for a Sensible account.
- Postman desktop app, or a command line with cURL installed.
Configure the extraction
To create example extraction configuration, follow the steps in Out-of-the-box extractions to add support for the 1040s document type to your account. You'll use this document type in the following steps.
Extract the data
To try out the extract_from_url endpoint, let's use an example document hosted in GitHub:
-
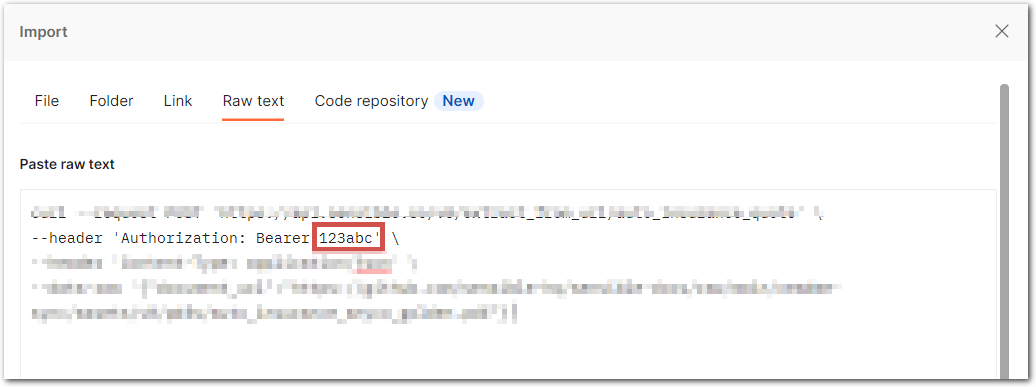
Copy the following code sample and replace
*YOUR_API_KEY*with your API key:curl --request POST 'https://api.sensible.so/v0/extract_from_url/1040s' \ --header 'Authorization: Bearer YOUR_API_KEY' \ --header 'Content-Type: application/json' \ --data-raw '{"document_url":"https://raw.githubusercontent.com/sensible-hq/sensible-docs/v0/assets/pdfs/1040_2021_sample.pdf"}' -
In your Postman workspace, click Import, select Raw text, paste the code sample, and follow the prompts to import to code sample.
-
Click Send, and you should see a response like:
{ "id": "14d82783-c12b-4e70-b0ae-ca1ce35a9836", "created": "2021-06-15T16:29:27.875Z", "status": "WAITING", "type": "1040s" }
Note: You don't have to specify the config for document (1040_2021) in this call. Sensible looks at all the configs for the document type (1040s), and automatically chooses the one that fits best!
Retrieve extraction
To retrieve the extraction results for the sample document, you have two options:
- Use the
/documentsendpoint. See the following steps. - Use a webhook. See Try a webhook.
To retrieve the extraction results with the /documents endpoint, take the following steps:
-
In a previous step on this page, you got back a result that included an extraction ID:
{ "id": "14d82783-c12b-4e70-b0ae-ca1ce35a9836" }Copy the document extraction
idfrom that response. You'll use it to download the document extraction. -
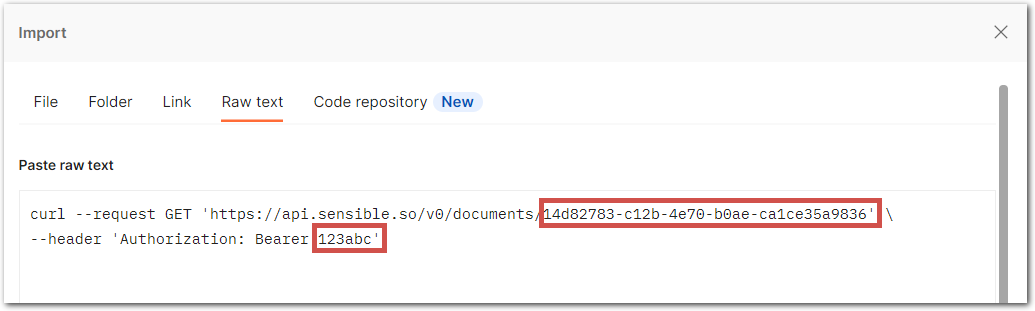
Copy the following code sample and replace
*YOUR_EXTRACTION_ID*and*YOUR_API_KEY*:
curl --request GET 'https://api.sensible.so/v0/documents/YOUR_EXTRACTION_ID' \
--header 'Authorization: Bearer YOUR_API_KEY'- In your Postman workspace, click Import, select Raw text, paste the code sample, and follow the prompts to import to code sample.
- Click Send. The response includes a
parsed_documentobject that looks something like the following:
{
"parsed_document": {
"year": {
"type": "string",
"value": "2021"
},
"filing_status.single": {
"type": "boolean",
"value": true
},
"filing_status.married_filing_jointly": {
"type": "boolean",
"value": false
},
"filing_status.married_filing_separately": {
"type": "boolean",
"value": false
},
"filing_status.head_of_household": {
"type": "boolean",
"value": false
},
"filing_status.qualifying_widow": {
"type": "boolean",
"value": false
},
"name": {
"type": "string",
"value": "Connor Roy"
},
"ssn": {
"type": "string",
"value": "337-18-2333"
}
}
}Updated 6 days ago