

Scale
Corrects the size of text in documents whose size varies, for example as a result of being photographed at different distances. ID cards and receipts are common examples of such documents. This preprocessor enables coordinates-based methods, such as the Region or Text Table methods, to work with such unpredictably scaled documents. For alternatives to this preprocessor, see Page transformation preprocessors.
Parameters
| key | value | description |
|---|---|---|
| type (required) | scale | |
| samples | array of objects | Array of example objects containing font heights for text matches in 100% scaled documents. Sensible compares the actual size of each match against the examples, then take an average of the ratios and use that to rescale the whole document. Sensible recommends the following practices: - Choose samples for which the font height does not vary relative to other font heights in the document. For example, don't create a sample that can match to both a heading 1 and a heading 4 style. - Choose samples that appear on each page, such as headers or footers. Each example object has the following parameters: match: a Match objecttargetHeight: the number in inches of the match at 100% scale. |
| perPage | boolean | If true, Sensible rescales each page individually against the Target Height parameter, taking the average of all matches' heights on that page rather than in the whole document. For example, if a tax return contains multiple W-2 forms, but each W-2 can be scanned at an unpredictable scale, then you can set this parameter to true and match on text such as the "Wage and Tax" and the W-2 titles in the W-2 form. |
Examples
The following example shows using the Per Page parameter to scale an ID card that has a different size on each page, where the second page contains the target size to standardize on.
Config
{
"preprocessors": [
{
"type": "scale",
"perPage": true,
"samples": [
{
"match": {
"type": "includes",
"text": "First",
"isCaseSensitive": true
},
"targetHeight": 0.22
}
]
}
],
"fields": [
{
"id": "white_house_tenure",
"anchor": "tenure",
"match": "all",
"method": {
"id": "region",
"start": "below",
"offsetX": -1.3,
"offsetY": 0,
"width": 2,
"height": 0.6
}
}
]
}
Example document
The following image shows the example document used with this example config:
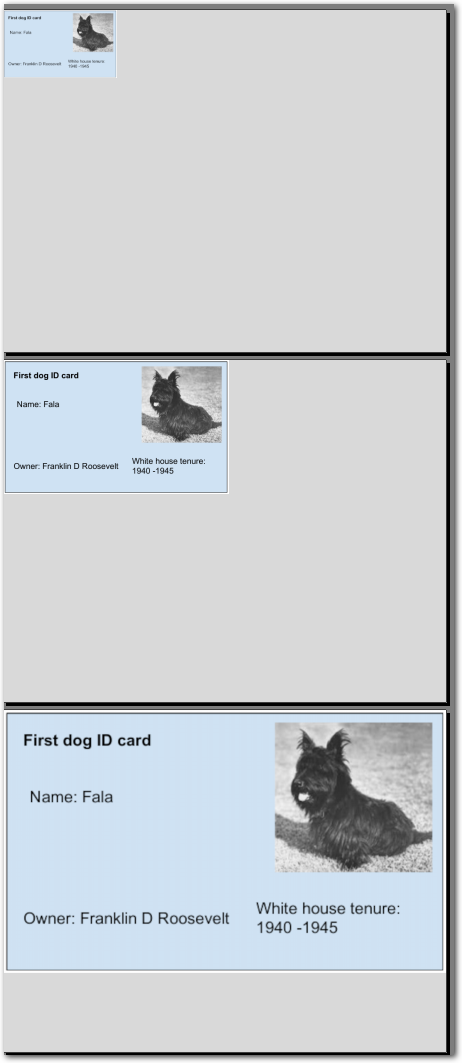
| Example document | Download link |
|---|
Output
{
"white_house_tenure": [
{
"type": "string",
"value": "1940-1945"
},
{
"type": "string",
"value": "1940-1945"
},
{
"type": "string",
"value": "1940-1945"
}
]
}Updated 7 months ago
Did this page help you?