

Overview
Welcome! Sensible is a developer-first platform for extracting structured data from documents, for example:
- business forms in PDF format
- email bodies and attachments
- spreadsheets
- PNGs and JPEGS of documents
Use Sensible to build document-automation features into your vertical SaaS products.
With Sensible's SenseML language, you can write extraction queries for any type of document:
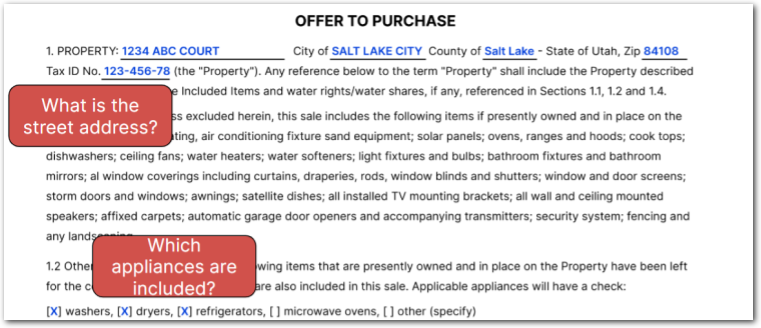
And get back key facts as JSON:
{
"street_address": {
"value": "1234 ABC COURT",
"type": "address"
},
"included_appliances": [
{
"value": "washers",
"type": "string"
},
{
"value": "dryers",
"type": "string"
},
{
"value": "refrigerators",
"type": "string"
}
]
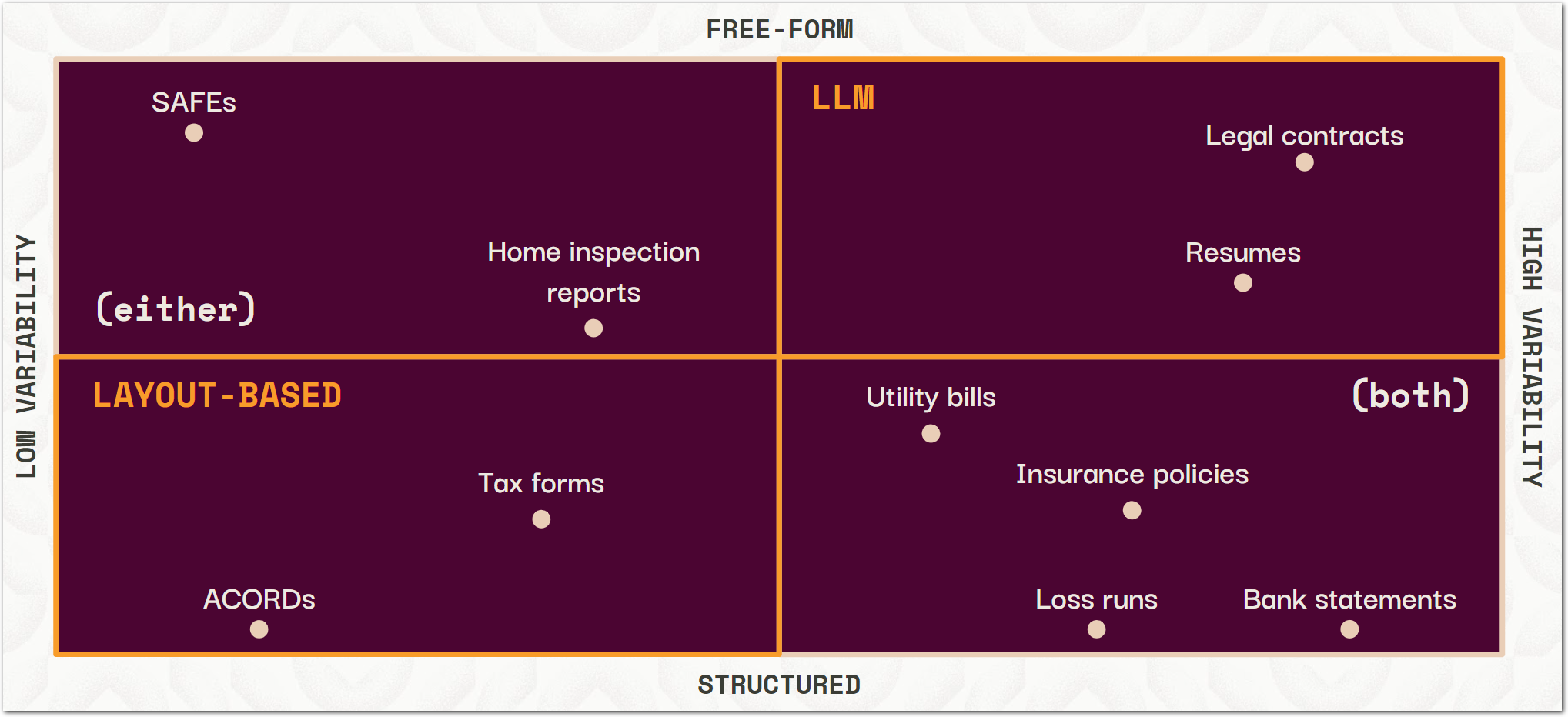
}Sensible is highly configurable. You can extract data in minutes by leveraging large language models (LLMs), or you can get fine-grained control with Sensible's visual, layout-based rules. By combining layout- and LLM-based extraction methods, Sensible supports the entire document landscape, from consistently laid-out, highly structured business forms to free-form, variable legal contracts :
Configurable data extraction
Configure your extractions using SenseML, Sensible's document-specific query language. SenseML combines the latest LLM techniques with visual layout-based rules to extract document primitives like rows, tables, checkboxes, sections, and more as JSON.
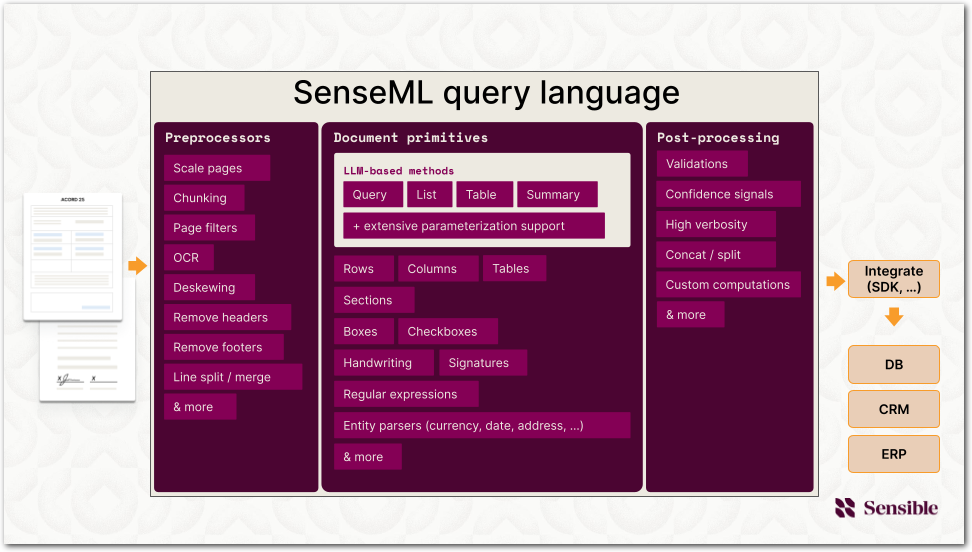
With SenseML, you can:
- Preprocess documents by correcting layout metadata problems, removing unwanted pages, and more, so that Sensible has a clean, standardized text representation of the document from which to extract structured data in a later step. For more information, see Preprocessors.
- Use "methods" to extract document primitives, like rows, columns, tables, boxes, checkbox status, and more. You can also parse extracted data types like currencies, dates, addresses, or your custom types. For more information, see Layout-based methods.
- Handle document variations in a set of similar documents (a "document type") by conditionally executing SenseML methods based on the document's contents.
- Post-process extracted document data. For example:
- Write logical validations like
customer ID is 9 digitsto throw custom errors and warnings about your extracted data. - Manipulate the extracted data schema with computed methods like concat, split, and custom logic. Or, completely transform Sensible's standardized
parsed_documentoutput into any schema to fit your data consupmtion needs using a JsonLogic postprocessor. - Get measures of accuracy for LLMs with confidence scores, and get overall measures of extraction completeness with extraction coverage scores.
- Write logical validations like
A field is the basic SenseML query unit for extracting a piece of document data. The output of a field is a JSON key-value pair that structures the extracted data. SenseML is the basis for Sensible's extraction workflow.
Here's an example of a field that extracts a table:
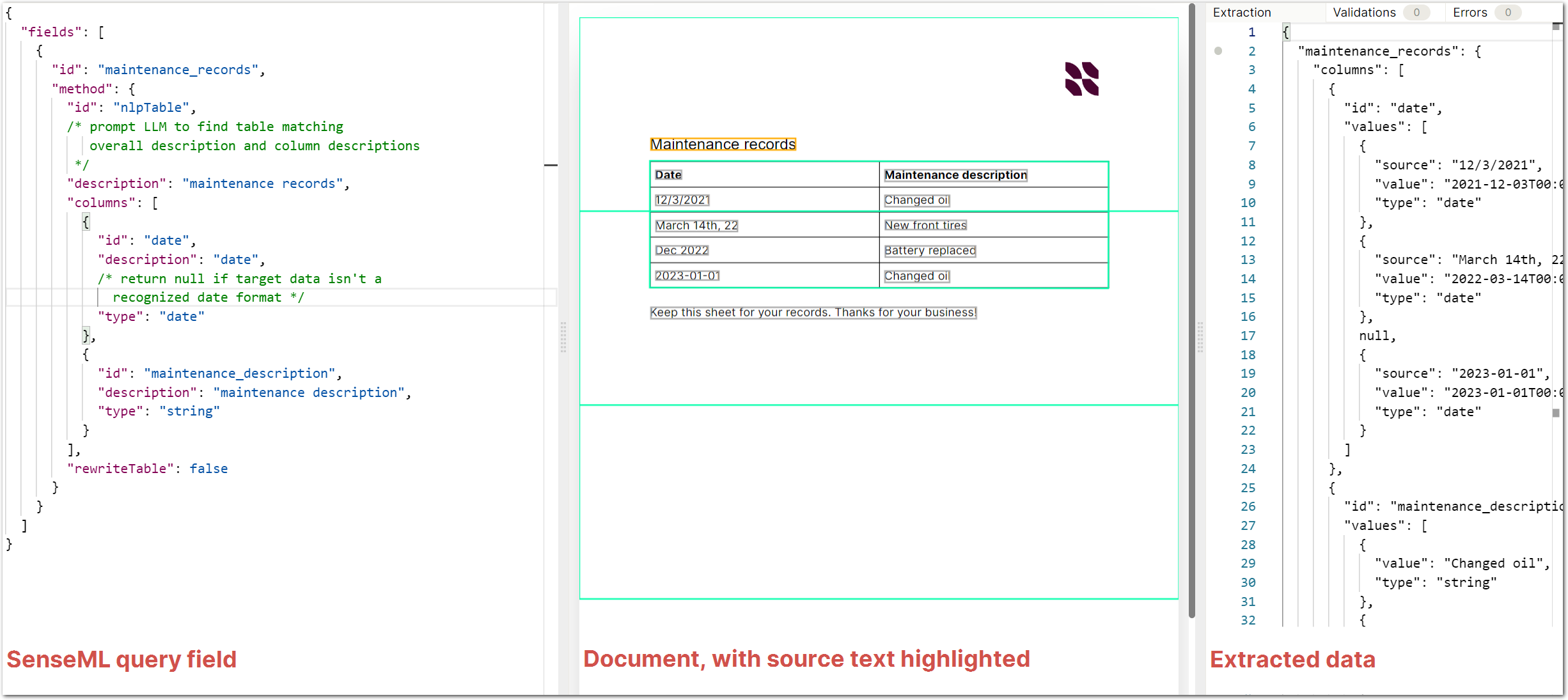
For more information about SenseML, see SenseML reference introduction.
DevOps platform for document data extraction
See the following image for a high-level overview of Sensible's document data extraction workflow:

For more information about this diagram, see DevOps platform.
Learn more
To use the Sensible platform, you'll:
- Learn to extract data, or use out-of-the-box supported document types. See Getting started and Getting started with layout-based extractions.
- Integrate using Sensible's API, SDKs, quick-extract UI, or other tools
- Validate extracted data by writing rules for custom errors like
extracted zip code is invalid format - Monitor extraction metrics in production
- Review and correct extracted data at the field level using the review UI
Updated 3 months ago