

Preprocessors
Use the following preprocessors to clean up your documents before extracting structured data. Preprocessors execute in the order you define them in an array.
| Preprocessor | Image | Notes |
|---|---|---|
| Deskew |  | Corrects the alignment of documents that are skewed, for example as a result of being photographed at an angle instead of straight on. |
| Ligature | 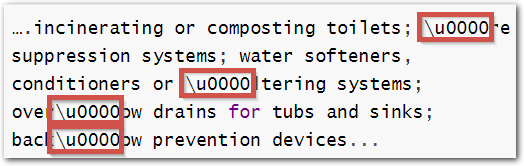 | Intelligently replaces Unicode ligatures with alphanumeric characters in a text extraction. |
| Linearize |  | Advanced alternative to multicolumn preprocessor |
| Merge Lines |  | Corrects oversplit lines. |
| Multicolumn | 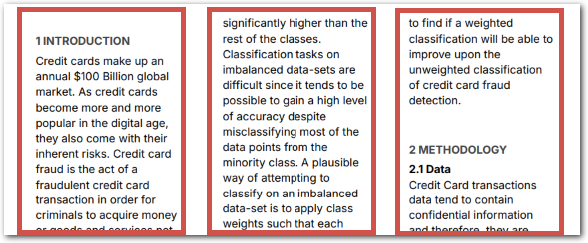 | Recognize multi-column formats |
| NLP | Advanced prompt configuration for each large language model (LLM)-based method in a config. | |
| OCR |  | Selectively OCRs pages in documents containing a mix of digitally generated text and text images (such as scanned text). If the whole PDF is a scan, you don't need to configure this preprocessor. |
| Page Range | Ignores pages outside the start page and end page. | |
| Remove Header |  | Removes repeating elements at the top of the page. Ignores header elements that overlap with the page's main body. |
| Remove Footer | 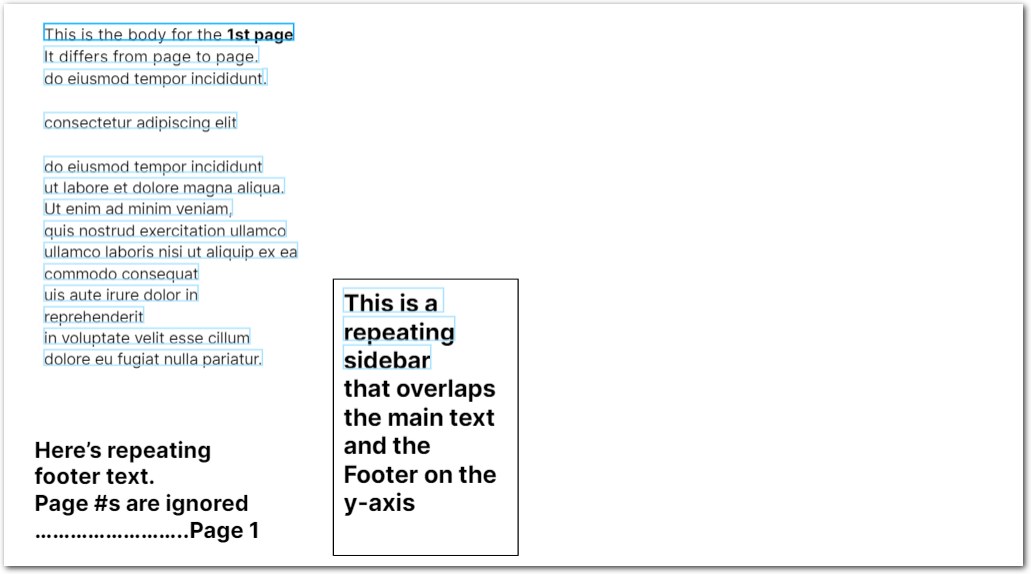 | Removes repeating elements at the bottom of the page. Ignores footer elements that overlap with the page's main body. |
| Remove Lines | 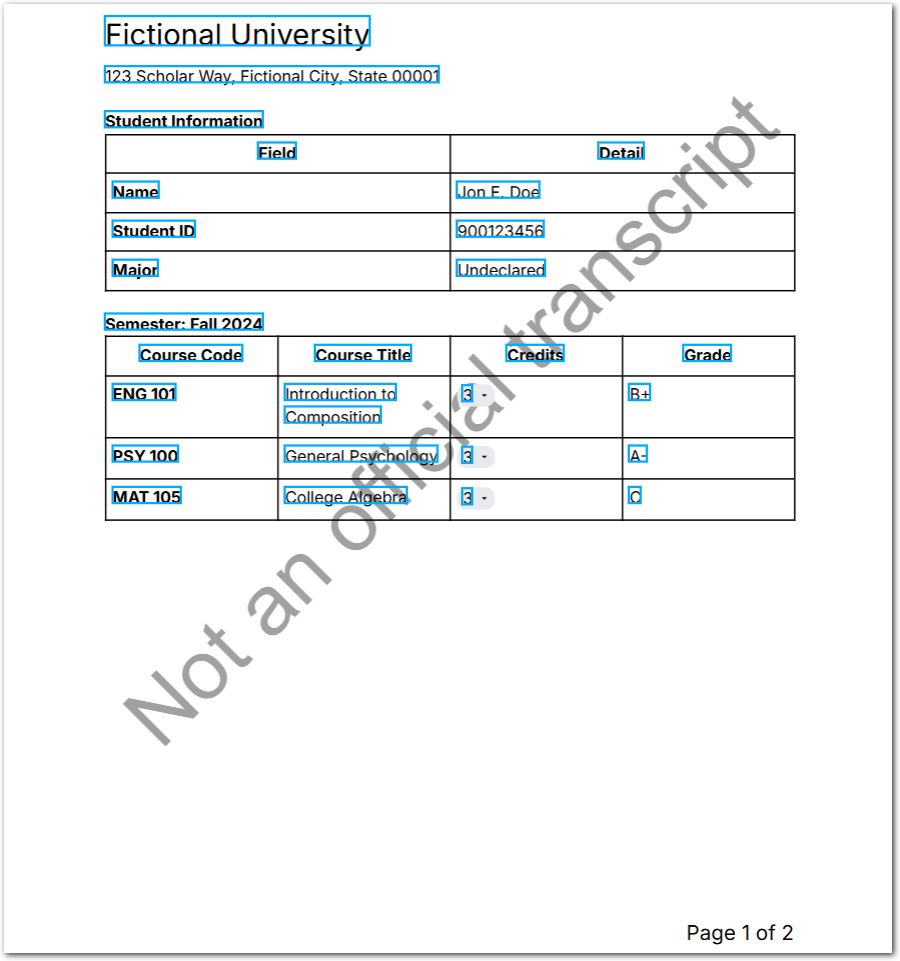 | Removes lines that match the specified text from all pages in the document. For example, use this preprocessor to remove watermarks. |
| Remove Page |  | Removes pages that match the specified text. |
| Rotate page |  | In most cases, Sensible corrects page rotation automatically. If it doesn't, configure this preprocessor. |
| Scale |  | Corrects the size of text in documents whose size varies, for example as a result of being scanned or photographed at different scales. |
| Split Lines |  | Corrects undersplit lines. |
Updated 5 months ago
Did this page help you?